[딥러닝] KNN
KNN
: K 최근접 이웃 알고리즘
- 이론
Machine Learning - (2) kNN 모델
이 글을 읽기 전에 반드시 참고하셔야 할 부분이 있음을 알려드립니다. 인터넷 상에 제 글이 검색이 되어 다른 분들도 한 번 혹은 그 이상은 거쳐가는 곳인 것은 사실이지만, 어디까지나 저는 Mac
onikaze.tistory.com
- anaconda prompt
pip install mglearn=> 모듈 다운로드
* knn1.py
import mglearn # pip install mglearn
import matplotlib.pyplot as plt
plt.rc('font', family='malgun gothic')
# -------------------------
# Classification
mglearn.plots.plot_knn_classification(n_neighbors=1)
plt.show()
mglearn.plots.plot_knn_classification(n_neighbors=3)
plt.show()
mglearn.plots.plot_knn_classification(n_neighbors=5)
plt.show()=> 가장 간단한 k-NN 알고리즘은 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용합니다.
=> 단순히 이 훈련 데이터 포인트의 출력이 예측이 됩니다.
import mglearn
mglearn.plots.plot_knn_classification(n_neighbors=) : classification knn 알고리즘. n_neighbors - k값.

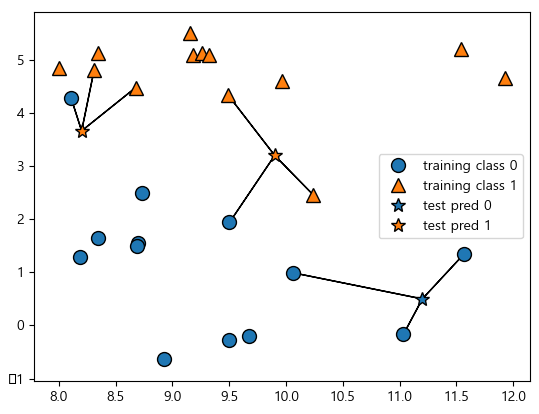

# Regression
mglearn.plots.plot_knn_regression(n_neighbors=1)
plt.show()
mglearn.plots.plot_knn_regression(n_neighbors=3)
plt.show()import mglearn
mglearn.plots.plot_knn_regression(n_neighbors=) : regression knn 알고리즘. n_neighbors - k값.

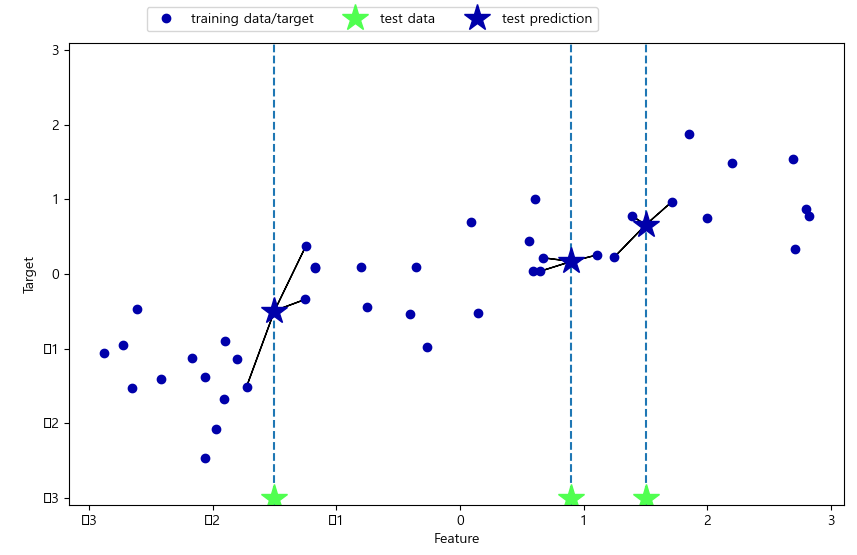
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge() # forge dataset load
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=12) # train, test로 나눔
print(X_train, ' ', X_train.shape) # [[ 8.92229526 -0.63993225] ... (19, 2)
print(X_test, ' ', X_test.shape) # (7, 2)
print(y_train) # [0 0 1 1 0 1 0 1 1 1 0 1 0 0 0 1 0 1 0]
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
print("test 예측: {}".format(model.predict(X_test)))
# test 예측: [0 0 1 0 1 1 1]
print("test 정확도: {:.2f}".format(model.score(X_test, y_test)))
# test 정확도: 0.86
print("train 정확도: {:.2f}".format(model.score(X_train, y_train)))
# train 정확도: 0.95
fig, axes = plt.subplots(1, 3, figsize=(10, 5))
for n_neighbors, ax in zip([1, 3, 9], axes):
model2 = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(model2, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} 이웃".format(n_neighbors))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend(loc=1)
plt.show()import mglearn
mglearn.datasets.make_forge() : forge dataset
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors=) : knn classification 알고리즘
model.score(x, y) : 정확도
mglearn.plots.plot_2d_separator(model2, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)

왼쪽 그림을 보면 이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라가고 있습니다.
이웃의 수를 늘릴수록 결정 경계는 더 부드러워집니다. 부드러운 경계는 더 단순한 모델을 의미합니다.
다시 말해 이웃을 적게 사용하면 모델의 복잡도가 높아지고([그림]의 오른쪽) 많이 사용하면 복잡도는 낮아집니다([그림]의 왼쪽).
훈련 데이터 전체 개수를 이웃의 수로 지정하는 극단적인 경우에는 모든 테스트 포인트가 같은 이웃(모든 훈련 데이터)을 가지게 되므로 테스트 포인트에 대한 예측은 모두 같은 값이 됩니다.
즉 훈련 세트에서 가장 많은 데이터 포인트를 가진 클래스가 예측값이 됩니다.
일반적으로 KNeighbors 분류기에 중요한 매개변수는 두 개입니다. 데이터 포인트 사이의 거리를 재는 방법과 이웃의 수입니다.
실제로 이웃의 수는 3개나 5개 정도로 적을 때 잘 작동하지만, 이 매개변수는 잘 조정해야 합니다.
거리 재는 방법은 기본적으로 유클리디안 거리 방식을 사용합니다.
breast_cancer dataset으로 실습
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# 1에서 10까지 n_neighbors를 적용
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors) # 모델 생성
clf.fit(X_train, y_train)
# train dataset 정확도 저장
training_accuracy.append(clf.score(X_train, y_train))
# test dataset 정확도 저장
test_accuracy.append(clf.score(X_test, y_test))
import numpy as np
print("평균 정확도 :", np.mean(test_accuracy))
# 평균 정확도 : 0.918881118881119
plt.plot(neighbors_settings, training_accuracy, label="훈련 정확도")
plt.plot(neighbors_settings, test_accuracy, label="테스트 정확도")
plt.ylabel("정확도")
plt.xlabel("n_neighbors")
plt.legend()
plt.show()from sklearn.datasets import load_breast_cancer
load_breast_cancer()

이 그림은 n_neighbors 수(x축)에 따른 훈련 세트와 테스트 세트 정확도(y축)를 보여줍니다.
실제 이런 그래프는 매끈하게 나오지 않지만, 여기서도 과대적합과 과소적합의 특징을 볼 수 있습니다
(이웃의 수가 적을수록 모델이 복잡해지므로 [그림]의 그래프가 수평으로 뒤집힌 형태입니다).
최근접 이웃의 수가 하나일 때는 훈련 데이터에 대한 예측이 완벽합니다.
하지만 이웃의 수가 늘어나면 모델은 단순해지고 훈련 데이터의 정확도는 줄어듭니다.
이웃을 하나 사용한 테스트 세트의 정확도는 이웃을 많이 사용했을 때보다 낮습니다.
이것은 1-최근접 이웃이 모델을 너무 복잡하게 만든다는 것을 설명해줍니다.
반대로 이웃을 10개 사용했을 때는 모델이 너무 단순해서 정확도는 더 나빠집니다.
정확도가 가장 좋을 때는 중간 정도인 여섯 개를 사용한 경우입니다.
참고 : 파이썬 라이브러리를 활용한 머신러닝 (한빛미디어 출판사)의 일부분을 사용했습니다.
* knn2.py
from sklearn.neighbors import KNeighborsClassifier
kmodel = KNeighborsClassifier(n_neighbors = 3, weights = 'distance')
train = [
[5, 3, 2],
[1, 3, 5],
[4, 5, 7]
]
label = [0, 1, 1]
import matplotlib.pyplot as plt
plt.plot(train, 'o')
plt.xlim([-1, 5])
plt.ylim([0, 10])
plt.show()scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
sklearn.neighbors.KNeighborsClassifier — scikit-learn 0.24.1 documentation
scikit-learn.org
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors = 3, weights = 'distance')

kmodel.fit(train, label)
pred = kmodel.predict(train)
print('pred :', pred) # pred : [0 1 1]
print('acc :', kmodel.score(train, label)) # acc : 1.0
new_data = [[1, 2, 8], [6, 4, 1]]
new_pred = kmodel.predict(new_data)
print('new_pred :', new_pred) # new_pred : [1 0]* regression_test.py
# 대표적인 분류/예측 모델로 Regression 연습
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from sklearn.metrics import r2_score
adver = pd.read_csv('../testdata/Advertising.csv', usecols=[1,2,3,4])
print(adver.head(2))
'''
tv radio newspaper sales
0 230.1 37.8 69.2 22.1
1 44.5 39.3 45.1 10.4
'''
x = np.array(adver.loc[:, 'tv':'newspaper'])
y = np.array(adver.sales)
print(x[:2]) # [[230.1 37.8 69.2] [ 44.5 39.3 45.1]]
print(y[:2]) # [22.1 10.4]
# KNeighborsRegressor
kmodel = KNeighborsRegressor(n_neighbors=3).fit(x, y)
print(kmodel)
kpred = kmodel.predict(x)
print('pred :', kpred[:5]) # pred : [20.4 10.43333333 8.56666667 18.2 14.2 ]
print('r2 :', r2_score(y, kpred)) # r2 : 0.968012077694316
print()
# LinearRegression
lmodel = LinearRegression().fit(x, y)
print(lmodel)
lpred = lmodel.predict(x)
print('pred :', lpred[:5]) # pred : [20.52397441 12.33785482 12.30767078 17.59782951 13.18867186]
print('r2 :', r2_score(y, lpred)) # r2 : 0.8972106381789522
print()
# RandomForestRegressor
rmodel = RandomForestRegressor(n_estimators=100, criterion='mse').fit(x, y)
print(rmodel)
rpred = rmodel.predict(x)
print('pred :', rpred[:5]) # pred : [21.942 10.669 8.859 18.281 13.44 ]
print('r2 :', r2_score(y, rpred)) # r2 : 0.9971466378876895
print()
# XGBRegressor
xmodel = XGBRegressor(n_estimators=100).fit(x, y)
print(xmodel)
xpred = xmodel.predict(x)
print('pred :', xpred[:5]) # pred : [22.095655 10.40437 9.302584 18.499216 12.9007015]
print('r2 :', r2_score(y, xpred)) # r2 : 0.9999996661140423
print()