ANOVA(analysis of variance)
: 독립변수 범주형(3개 이상), 종속변수 연속형
| 독립변수 x | 종속변수 y | 분석 방법 | |
| 범주형 | 범주형 |
카이제곱 검정(교차분석) | 일원 카이제곱 : 변인 1 개 import scipy.stats as stats stats.chisquare() |
| 일원 카이제곱 : 변인 2 개 이상 stats.chi2_contingency() |
|||
| 범주형 |
연속형 | T 검정 : 범주형 값 2개 이하 |
단일 표본 검정 (one sample t-test) : 집단 1개 stats.ttest_1samp(데이터, popmean=모집단 평균) |
| 독립 표본 검정(independent samples t test) : 두 집단 정규분포/ 분산 동일 stats.ttest_ind(데이터,..., , equal_var=False) |
|||
| 대응 표본 검정(paired samples t test) : 동일한 관찰 대상의 처리 전과 처리 후 비교 stats.ttest_rel(데이터, .. ) |
|||
| ANOVA :범주형 값 3개 이상 |
일원 분산분석(one-way anova) : 1개의 요인에 집단이 3개 import statsmodels.api as sm from statsmodels.formula.api import ols model = ols('종속변수 ~ 독립변수', data).fit() sm.stats.anova_lm(model, type=2) model = ols('종속변수 ~ 독립변수1 + 독립변수2', data).fit() stats.f_oneway(gr1, gr2, gr3) |
||
| 연속형 | 범주형 | 로지스틱 회귀 분석 | |
| 연속형 | 연속형 | 회귀분석, 구조 방정식 |
일원 분산분석(one-way anova)
: 1개의 요인에 집단이 3개
실습 1 : 세 가지 교육방법을 적용하여 1개월 동안 교육받은 교육생 80 명을 대상으로 실기시험을 실시 .
귀무가설 : 교육생을 대상으로 3가지 교육방법에 따른 실기시험 평균의 차이가 없다.
대립가설 : 교육생을 대상으로 3가지 교육방법에 따른 실기시험 평균의 차이가 있다.
* anova1.py
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
data = pd.read_csv('../testdata/three_sample.csv')
print(data.head(3), data.shape)
'''
no method survey score
0 1 1 1 72
1 2 3 1 87
2 3 2 1 78 (80, 4)
'''
print(data.describe())
- 이상치 제거
data = data.query('score <= 100')
plt.boxplot(data.score)
#plt.show()
# 독립성 : 상관관계를 확인가능
# 등분산성
result = data[['method', 'score']]
m1 = result[result['method'] == 1]
m2 = result[result['method'] == 2]
m3 = result[result['method'] == 3]
#print(m1)
score1 = m1['score']
score2 = m2['score']
score3 = m3['score']
print('등분산성 :', stats.levene(score1, score2, score3).pvalue) # 등분산성 : 0.11322 > 0.05 이므로 만족
print('등분산성 :', stats.fligner(score1, score2, score3).pvalue) # 등분산성 : 0.10847
print('등분산성 :', stats.bartlett(score1, score2, score3).pvalue) # 등분산성 : 0.15251
- 정규성
print(stats.shapiro(score1))
print('정규성 확인 :', stats.ks_2samp(score1, score2).pvalue) # pvalue=0.3096 > 0.05 이므로 만족
print('정규성 확인 :', stats.ks_2samp(score1, score3).pvalue) # pvalue=0.7162 > 0.05 이므로 만족
print('정규성 확인 :', stats.ks_2samp(score2, score3).pvalue) # pvalue=0.7724 > 0.05 이므로 만족stats.ks_2samp(data1, data2).pvalue : 정규성 확인
print('교육방법별 건수')
data2 = pd.crosstab(index = data['method'], columns = 'count')
print(data2)
'''
교육방법별 건수
col_0 count
method
1 26
2 28
3 24
'''
print('교육방법별 만족 여부 건수')
data3 = pd.crosstab(data['method'], data['survey'])
data3.index = ['방법1', '방법2', '방법3']
data3.columns = ['만족', '불만족']
print(data3)
'''
교육방법별 만족 여부 건수
만족 불만족
방법1 9 17
방법2 10 18
방법3 8 16
'''
- ANOVA
import statsmodels.api as sm
from statsmodels.formula.api import ols
model = ols('score ~ method', data).fit()
table = sm.stats.anova_lm(model, type=2)
print(table)
''' df sum_sq mean_sq F PR(>F)
method 1.0 27.980888 27.980888 0.122228 0.727597
Residual 76.0 17398.134497 228.922822 NaN NaN
'''
print(model.summary())import statsmodels.api as sm
from statsmodels.formula.api import ols
model = ols('종속변수 ~ 독립변수', data).fit() : model
sm.stats.anova_lm(model, type=2) : anova
p-value : 0.727597 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 교육생을 대상으로 3가지 교육방법에 따른 실기시험 평균의 차이가 없다.
# ANOVA 다중회귀 : 독립변수 2
model2 = ols('score ~ method + survey', data).fit()
table2 = sm.stats.anova_lm(model2, type=2)
print(table2)
'''
df sum_sq mean_sq F PR(>F)
method 1.0 27.980888 27.980888 0.120810 0.729131
survey 1.0 27.324458 27.324458 0.117976 0.732201
Residual 75.0 17370.810039 231.610801 NaN NaN
'''
# mean_sq = sum_sq / df
import numpy as np
print()
print(np.mean(score1)) # 67.38461538461539
print(np.mean(score2)) # 68.35714285714286
print(np.mean(score3)) # 68.875
print()model = ols('종속변수 ~ 독립변수1 + 독립변수2', data).fit() : 다중회귀
사후 검정(Post Hoc Test)
: 가능한 모든 쌍을 비교하며 예상되는 표준 오류보다 큰 두 가지 방법의 차이를 정확하게 식별하는 데 사용 할 수 있다.
: 그룹 간에 평균값 차이가 의미가 있는 지 확인.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tResult = pairwise_tukeyhsd(data, data.method)
print(tResult)
'''
Multiple Comparison of Means - Tukey HSD, FWER=0.05
=====================================================
group1 group2 meandiff p-adj lower upper reject
-----------------------------------------------------
1 2 3.8352 0.7997 -11.3827 19.053 False
1 3 -0.0577 0.9 -15.8743 15.7589 False
2 3 -3.8929 0.8018 -19.436 11.6503 False
-----------------------------------------------------
'''
tResult.plot_simultaneous()
plt.show()from statsmodels.stats.multicomp import pairwise_tukeyhsd
result = pairwise_tukeyhsd(data, data.독립변수) : 사후검정.
result.plot_simultaneous() : 시각화.

일원분산으로 집단 간의 평균 차이 검증
강남구 소재 GS 편의점 3개 지역 , 알바생의 급여에 대한 평균의 차이를 검정
귀무가설 : 3개 지역 급여에 대한 평균에 차이가 없다.
대립가설 : 3개 지역 급여에 대한 평균에 차이가 있다.
* anova2.py
import scipy.stats as stats
import pandas as pd
import numpy as np
import urllib.request
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
url = "https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/group3.txt"
data = np.genfromtxt(urllib.request.urlopen(url), delimiter=',')
print(data)
'''
[[243. 1.]
[251. 1.]
[275. 1.]
[291. 1.]
...
'''np.genfromtxt(urllib.request.urlopen(url), delimiter=',') : url 읽기
# 세 개 집단
gr1 = data[data[:, 1] == 1, 0]
gr2 = data[data[:, 1] == 2, 0]
gr3 = data[data[:, 1] == 3, 0]
print(gr1, np.average(gr1))
# [243. 251. 275. 291. 347. 354. 380. 392.] 316.625
print(gr2, np.average(gr2))
# [206. 210. 226. 249. 255. 273. 285. 295. 309.] 256.44444444444446
print(gr3, np.average(gr3))
# [241. 258. 270. 293. 328.] 278.0
# 정규성
print(stats.shapiro(gr1)) # pvalue=0.3336 > 0.05 정규성 만족
print(stats.shapiro(gr2)) # pvalue=0.6561 > 0.05 정규성 만족
print(stats.shapiro(gr3)) # pvalue=0.8324 > 0.05 정규성 만족
# 등분산성
print(stats.bartlett(gr1, gr2, gr3)) # pvalue=0.3508 > 0.05 등분산성 만족
# 시각화
plot_data = [gr1, gr2, gr3]
plt.boxplot(plot_data)
#plt.show()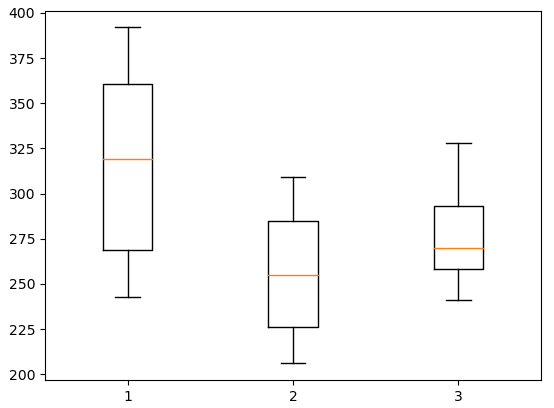
# 방법 1
df = pd.DataFrame(data, columns=['value', 'group'])
print(df)
'''
value group
0 243.0 1.0
1 251.0 1.0
2 275.0 1.0
3 291.0 1.0
4 347.0 1.0
5 354.0 1.0
'''
model = ols('value ~ C(group)', df).fit() # C(변수명 + ..) : 범주형임을 명시적으로 표시
print(anova_lm(model))
print()
# 방법 2
f_statistic, p_val = stats.f_oneway(gr1, gr2, gr3)
print('f_statistic : {}, p_val : {}'.format(f_statistic, p_val))
# f_statistic : 3.7113359882669763, p_val : 0.043589334959178244model = ols('종속변수 ~ C(독립변수, ... )', df).fit() : C(변수명 + ..) : 범주형임을 명시적으로 표시
f_statistic, p_val = stats.f_oneway(gr1, gr2, gr3) : 일원 분산 검정
일원 분산분석
어느 음식점의 매출자료와 날씨 자료를 이용하여 온도에 따른 매출의 평균의 차이에 대한 검정.
온도를 3 그룹으로 분리.
귀무가설 : 온도에 따른 매출액 평균에 차이가 없다.
대립가설 : 온도에 따른 매출액 평균에 차이가 있다.
* anova3.py
import numpy as np
import scipy.stats as stats
import pandas as pd
import matplotlib.pyplot as plt
# 매출자료
sales_data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/tsales.csv', dtype={'YMD':'object'})
print(sales_data.head(3)) # 328행
'''
YMD AMT CNT
0 20190514 0 1
1 20190519 18000 1
2 20190521 50000 4
'''
print(sales_data.info())
# 날씨 자료
wt_data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/tweather.csv')
print(wt_data.head(3)) # 702행
'''
stnId tm avgTa minTa maxTa sumRn maxWs avgWs ddMes
0 108 2018-06-01 23.8 17.5 30.2 0.0 4.3 1.9 0.0
1 108 2018-06-02 23.4 17.6 30.1 0.0 4.5 2.0 0.0
2 108 2018-06-03 24.0 16.9 30.8 0.0 4.2 1.6 0.0
'''
print(wt_data.info())
# 날짜를 기준으로 join
wt_data.tm = wt_data.tm.map(lambda x : x.replace('-','')) # wt_data.tm에서 '-' 제거
#print(wt_data.head(3))
frame = sales_data.merge(wt_data, how='left', left_on='YMD', right_on='tm') # join
print(frame.head(3), frame.shape) # (328, 12)
'''
YMD AMT CNT stnId tm ... maxTa sumRn maxWs avgWs ddMes
0 20190514 0 1 108 20190514 ... 26.9 0.0 4.1 1.6 0.0
1 20190519 18000 1 108 20190519 ... 21.6 22.0 2.7 1.2 0.0
2 20190521 50000 4 108 20190521 ... 23.8 0.0 5.9 2.9 0.0
'''
print(frame.columns)
# 분석에 참여할 칼럼만 추출
data = frame.iloc[:, [0,1,7,8]]
print(data.head(3))
'''
YMD AMT maxTa sumRn
0 20190514 0 26.9 0.0
1 20190519 18000 21.6 22.0
2 20190521 50000 23.8 0.0
'''
- 일별 최고온도를 구간설정을 통해 연속형 변수를 명목형(범주형) 변수로 변경
print(data.maxTa.describe())
plt.boxplot(data.maxTa)
plt.show()
# 온도 추움, 보통, 더움(0, 1, 2)
data['Ta_gubun'] = pd.cut(data.maxTa, bins = [-5, 8, 24, 37], labels = [0, 1, 2])
print(data.head(5))
#print(data.isnull().sum())
#data = data[data.Ta_gubun.notna()] # na가 있다면 제거
print(data['Ta_gubun'].unique())
# 상관관계
print(data.corr())
'''
AMT maxTa sumRn
AMT 1.000000 -0.660066 -0.080907
maxTa -0.660066 1.000000 0.119268
sumRn -0.080907 0.119268 1.000000
'''# 3그룹으로 데이터를 나눈 후 등분산성, 정규성 검정.
x1 = np.array(data[data.Ta_gubun == 0].AMT)
x2 = np.array(data[data.Ta_gubun == 1].AMT)
x3 = np.array(data[data.Ta_gubun == 2].AMT)
print(x1)
print(x2)
print(x3)
print(stats.levene(x1, x2, x3)) # pvalue=0.0390 < 0.05 등분산성 만족 X
print(stats.ks_2samp(x1, x2).pvalue) # 9.28938415079017e-09 < 0.05 정규성 만족 X
print(stats.ks_2samp(x1, x3).pvalue) # 1.198570472122961e-28 < 0.05 정규성 만족 X
print(stats.ks_2samp(x2, x3).pvalue) # 1.4133139103478243e-13 < 0.05 정규성 만족 X
# 온도별 매출액 평균
spp = data.loc[:, ['AMT', 'Ta_gubun']]
print(spp.groupby('Ta_gubun').mean())
print(pd.pivot_table(spp, index = ['Ta_gubun'], aggfunc = 'mean'))
'''
AMT
Ta_gubun
0 1.032362e+06
1 8.181069e+05
2 5.537109e+05
'''# ANOVA 진행
sp = np.array(spp)
group1 = sp[sp[:, 1] == 0, 0]
group2 = sp[sp[:, 1] == 1, 0]
group3 = sp[sp[:, 1] == 2, 0]
print(group1)
print(group2)
print(group3)
print(stats.f_oneway(group1, group2, group3))pvalue=2.360737101089604e-34 < 0.05 이므로 귀무가설 기각.
# 대립가설 : 온도에 따른 매출액 평균에 차이가 있다.
등분산성 만족 하지않을 경우 Welch's ANOVA를 사용
anaconda prompt 접속
pip install pingouinfrom pingouin import welch_anova
df = data
print(welch_anova(data = df, dv = 'AMT', between='Ta_gubun')) # p-unc = 7.907874e-35 < 0.05
'''
Source ddof1 ddof2 F p-unc np2
0 Ta_gubun 2 189.6514 122.221242 7.907874e-35 0.379038
'''
정규성을 만족하지 못한 경우 kruskal-wallis test 사용
print(stats.kruskal(group1, group2, group3))
#KruskalResult(statistic=132.7022591443371, pvalue=1.5278142583114522e-29)pvalue < 0.05 이므로 귀무가설 기각.
#결론 : 온도에 따른 매출액의 차이가 있다.
# 사후 검정
from statsmodels.stats.multicomp import pairwise_tukeyhsd
posthoc = pairwise_tukeyhsd(spp['AMT'], spp['Ta_gubun'])
print(posthoc)
'''
Multiple Comparison of Means - Tukey HSD, FWER=0.05
=================================================================
group1 group2 meandiff p-adj lower upper reject
-----------------------------------------------------------------
0 1 -214255.4486 0.001 -296759.7083 -131751.189 True
0 2 -478651.3813 0.001 -561488.5315 -395814.2311 True
1 2 -264395.9327 0.001 -333329.5099 -195462.3555 True
-----------------------------------------------------------------
'''
posthoc.plot_simultaneous()
plt.show()

이원 분산분석
: 요인 2개
귀무가설 : 태아와 관측자수는 태아의 머리둘레의 평균과 관련이 없다.
대립가설 : 태아와 관측자수는 태아의 머리둘레의 평균과 관련이 있다.
* anova.py
import scipy.stats as stats
import pandas as pd
import numpy as np
import urllib.request
import matplotlib.pyplot as plt
plt.rc('font', family="malgun gothic")
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
url = "https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/group3_2.txt"
data = pd.read_csv(urllib.request.urlopen(url), delimiter=',')
print(data)
'''
머리둘레 태아수 관측자수
0 14.3 1 1
1 14.0 1 1
2 14.8 1 1
3 13.6 1 2
4 13.6 1 2
'''
data.boxplot(column='머리둘레', by='태아수', grid=False)
plt.show()

reg = ols('data["머리둘레"] ~ C(data["태아수"]) + C(data["관측자수"])', data = data).fit()
result = anova_lm(reg, type=2)
print(result)
'''
df sum_sq mean_sq F PR(>F)
C(data["태아수"]) 2.0 324.008889 162.004444 2023.182239 1.006291e-32
C(data["관측자수"]) 3.0 1.198611 0.399537 4.989593 6.316641e-03
Residual 30.0 2.402222 0.080074 NaN NaN
'''
# 두개의 요소 상호작용이 있는 형태로 처리
formula = '머리둘레 ~ C(태아수) + C(관측자수) + C(태아수):C(관측자수)'
reg2 = ols(formula, data).fit()
print(reg2)
result2 = anova_lm(reg2, type=2)
print(result2)
'''
df sum_sq mean_sq F PR(>F)
C(태아수) 2.0 324.008889 162.004444 2113.101449 1.051039e-27
C(관측자수) 3.0 1.198611 0.399537 5.211353 6.497055e-03
C(태아수):C(관측자수) 6.0 0.562222 0.093704 1.222222 3.295509e-01
Residual 24.0 1.840000 0.076667 NaN NaN
'''p-value PR(>F) C(태아수):C(관측자수) : 3.295509e-01 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 태아와 관측자수는 태아의 머리둘레의 평균과 관련이 없다.
jikwon 테이블 정보로 chi, t검정, anova
* anova5_t.py
import MySQLdb
import ast
import pandas as pd
import numpy as np
import scipy.stats as stats
import statsmodels.stats.api as sm
import matplotlib.pyplot as plt
try:
with open('mariadb.txt', 'r') as f:
config = f.read()
except Exception as e:
print('err :', e)
config = ast.literal_eval(config)
conn = MySQLdb.connect(**config)
cursor = conn.cursor()print("=================================================================")
print(' * 교차분석 (이원 카이제곱 검정 : 각 부서(범주형)와 직원평가 점수(범주형) 간의 관련성 분석) *')
# 독립변수 : 범주형, 종속변수 : 범주형
# 귀무가설 : 각 부서와 직원평가 점수 간 관련이 없다.(독립)
# 대립가설 : 각 부서와 직원평가 점수 간 관련이 있다.
df = pd.read_sql("select * from jikwon", conn)
print(df.head(3))
'''
jikwon_no jikwon_name buser_num ... jikwon_ibsail jikwon_gen jikwon_rating
0 1 홍길동 10 ... 2008-09-01 남 a
1 2 한송이 20 ... 2010-01-03 여 b
2 3 이순신 20 ... 2010-03-03 남 b
'''
buser = df['buser_num']
rating = df['jikwon_rating']
ctab = pd.crosstab(buser, rating) # 교차표 작성
print(ctab)
'''
jikwon_rating a b c
buser_num
10 5 1 1
20 3 6 3
30 5 2 0
40 2 2 0
'''
chi, p, df, exp = stats.chi2_contingency(ctab)
print('chi : {}, p : {}, df : {}'.format(chi, p, df))
# chi : 7.339285714285714, p : 0.2906064076671985, df : 6
# p-value : 0.2906 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 각 부서와 직원평가 점수 간 관련이 없다.(독립)print("=================================================================")
print(' * 교차분석 (이원 카이제곱 검정 : 각 부서(범주형)와 직급(범주형) 간의 관련성 분석) *')
# 귀무가설 : 각 부서와 직급 간 관련이 없다.(독립)
# 대립가설 : 각 부서와 직급 간 관련이 있다.
df2 = pd.read_sql("select buser_num, jikwon_jik from jikwon", conn)
print(df2.head(3))
buser = df2.buser_num
jik = df2.jikwon_jik
ctab2 = pd.crosstab(buser, jik) # 교차표 작성
print(ctab2)
chi, p, df, exp = stats.chi2_contingency(ctab2)
print('chi : {}, p : {}, df : {}'.format(chi, p, df))
# chi : 9.620617477760335, p : 0.6492046290079438, df : 12
# p-value : 0.6492 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 각 부서와 직급 간 관련이 없다.(독립)
print()print("=================================================================")
print(' * 차이분석 (t-test : 10, 20번 부서(범주형)와 평균 연봉(연속형) 간의 차이 분석) *')
# 독립변수 : 범주형, 종속변수 : 연속형
# 귀무가설 : 두 부서 간 연봉 평균의 차이가 없다.
# 대립가설 : 두 부서 간 연봉 평균의 차이가 있다.
#df_10 = pd.read_sql("select buser_num, jikwon_pay from jikwon where buser_num in (10, 20)", conn)
df_10 = pd.read_sql("select buser_num, jikwon_pay from jikwon where buser_num = 10", conn)
df_20 = pd.read_sql("select buser_num, jikwon_pay from jikwon where buser_num = 20", conn)
buser_10 = df_10['jikwon_pay']
buser_20 = df_20['jikwon_pay']
print('평균 :',np.mean(buser_10), ' ', np.mean(buser_20))
# 평균 : 5414.285714285715 4908.333333333333
t_result = stats.ttest_ind(buser_10, buser_20)
print(t_result)
# pvalue=0.6523 > 0.05 이므로 귀무가설 채택
# 귀무가설 : 두 부서 간 연봉 평균의 차이가 없다.
print()print("=================================================================")
print(' * 분산분석 (ANOVA : 각 부서(부서라는 1개의 요인에 4그룹으로 분리. 범주형)와 평균 연봉(연속형) 간의 차이 분석) *')
# 독립변수 : 범주형, 종속변수 : 연속형
# 귀무가설 : 4개의 부서 간 연봉 평균의 차이가 없다.
# 대립가설 : 4개의 부서 간 연봉 평균의 차이가 있다.
df3 = pd.read_sql("select buser_num, jikwon_pay from jikwon", conn)
buser = df3['buser_num']
pay = df3['jikwon_pay']
gr1 = df3[df3['buser_num'] == 10 ]['jikwon_pay']
gr2 = df3[df3['buser_num'] == 20 ]['jikwon_pay']
gr3 = df3[df3['buser_num'] == 30 ]['jikwon_pay']
gr4 = df3[df3['buser_num'] == 40 ]['jikwon_pay']
print(gr1)
# 시각화
plt.boxplot([gr1, gr2, gr3, gr4])
#plt.show()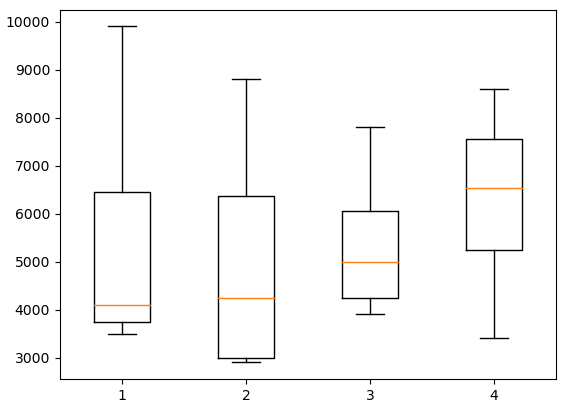
# 방법 1
f_sta, pv = stats.f_oneway(gr1, gr2, gr3, gr4)
print('f : {}, p : {}'.format(f_sta, pv))
# f : 0.41244077160708414, p : 0.7454421884076983
# p > 0.05 이므로 귀무가설 채택
# 귀무가설 : 4개의 부서 간 연봉 평균의 차이가 없다.
# 방법 2
lmodel = ols('jikwon_pay ~ C(buser_num)', data = df3).fit()
result = anova_lm(lmodel, type=2)
print(result)
'''
df sum_sq mean_sq F PR(>F)
C(buser_num) 3.0 5.642851e+06 1.880950e+06 0.412441 0.745442
Residual 26.0 1.185739e+08 4.560535e+06 NaN NaN
'''
# P : 0.745442 > 0.05 이므로 귀무가설 채택
# 귀무가설 : 4개의 부서 간 연봉 평균의 차이가 없다.
# 사후검정
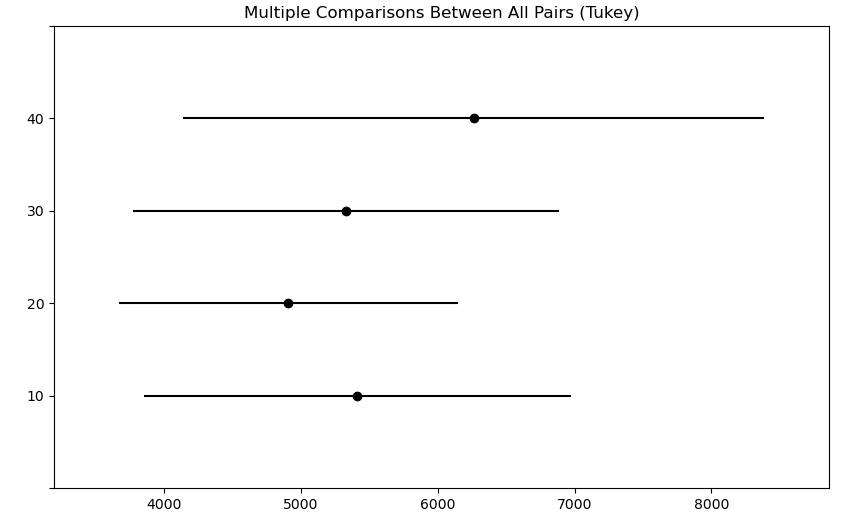
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tukey = pairwise_tukeyhsd(df3.jikwon_pay, df3.buser_num)
print(tukey)
'''
Multiple Comparison of Means - Tukey HSD, FWER=0.05
==========================================================
group1 group2 meandiff p-adj lower upper reject
----------------------------------------------------------
10 20 -505.9524 0.9 -3292.2958 2280.391 False
10 30 -85.7143 0.9 -3217.2939 3045.8654 False
10 40 848.2143 0.9 -2823.8884 4520.3169 False
20 30 420.2381 0.9 -2366.1053 3206.5815 False
20 40 1354.1667 0.6754 -2028.326 4736.6593 False
30 40 933.9286 0.8955 -2738.1741 4606.0312 False
'''
tukey.plot_simultaneous()
plt.show()
'BACK END > Deep Learning' 카테고리의 다른 글
| [딥러닝] 선형회귀 (0) | 2021.03.10 |
|---|---|
| [딥러닝] 공분산, 상관계수 (0) | 2021.03.10 |
| [딥러닝] 이항검정 (0) | 2021.03.10 |
| [딥러닝] T 검정 (0) | 2021.03.05 |
| [딥러닝] 카이제곱 (0) | 2021.03.04 |