회귀분석 Regression
: 각각의 데이터에 대한 잔차 제곱합이 최소가 되는 추세선을 만들고, 이를 통해 독립 변수가 종속변수에 얼마나 영향을 주는지 인과관계를 분석.
: 독립변수 - 연속형, 종속변수 - 연속형.
: 두 변수는 상관관계 및 인과관계가 있어야한다. (상관계수 > 0.3)
: 정량적인 모델 생성.
- 기계 학습(지도학습) : 학습을 통해 모델 생성 후, 새로운 데이터에 대한 예측 및 분류
선형회귀 Linear Regression
최소 제곱법(Least Square Method)
Y = a + b * X

선형회귀분석의 기존 가정 충족 조건
- 선형성 : 독립변수(feature)의 변화에 따라 종속변수도 일정 크기로 변화해야 한다.
- 정규성 : 잔차항이 정규분포를 따라야 한다.
- 독립성 : 독립변수의 값이 서로 관련되지 않아야 한다.
- 등분산성 : 그룹간의 분산이 유사해야 한다. 독립변수의 모든 값에 대한 오차들의 분산은 일정해야 한다.
- 다중공선성 : 다중회귀 분석 시 3 개 이상의 독립변수 간에 강한 상관관계가 있어서는 안된다.
- 최소 제곱해를 선형 행렬 방정식으로 얻기
* linear_reg1.py
import numpy.linalg as lin
import numpy as np
import matplotlib.pyplot as plt
x = np.array([0, 1, 2, 3])
y = np.array([-1, 0.2, 0.9, 2.1])
plt.plot(x, y)
plt.grid(True)
plt.show()
A = np.vstack([x, np.ones(len(x))]).T
print(A)
'''
[[0. 1.]
[1. 1.]
[2. 1.]
[3. 1.]]
'''
# y = mx + c
m, c = np.linalg.lstsq(A, y, rcond=None)[0]
print('기울기 :', m, ' y절편:', c) # 기울기 : 0.9999999999999997 y절편 : -0.949999999999999
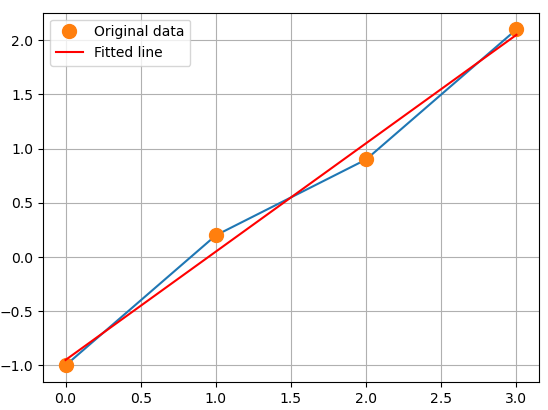
plt.plot(x, y, 'o', label='Original data', markersize=10)
plt.plot(x, m*x + c, 'r', label='Fitted line')
plt.legend()
plt.show()np.vstack(x, y) : x에 y 행 추가
np.ones(x) : x X x의 1로 채워진 행렬 생성
x.T : 행열 변경
import numpy.linalg as lin
lin.lstsq() : 최소제곱법
# yhat = 0.9999999999999997 * x -0.949999999999999
print(0.9999999999999997 * 1 -0.949999999999999) # 0.05000000000000071
print(0.9999999999999997 * 3 -0.949999999999999) # 2.0500000000000003
print(0.9999999999999997 * 123 -0.949999999999999) # 122.04999999999995
모델 생성
* linear_reg2.py
방법 1 : make_regression을 사용, model X
import statsmodels.api as sm
from sklearn.datasets import make_regression
import numpy as np
np.random.seed(12)
x, y, coef = make_regression(n_samples=50, n_features=1, bias=100, coef=True)
print('x :{}, y:{}, coef:{}'.format(x, y, coef))
'''
x :[[-1.70073563]
[-0.67794537]
y:[ -52.17214291 39.34130801
'''
# 기울기 coef:89.47430739278907
# 회귀식 y = a + bx y = 100 + 89.47430739278907 * x
y_pred = 100 + 89.47430739278907 * -1.70073563
print('y_pred :', y_pred) # y_pred : -52.17214255248879
xx = x
yy = y
방법 2 : Linear Regression을 사용. model O
from sklearn.linear_model import LinearRegression
model = LinearRegression()
fit_model = model.fit(xx, yy) # 학습 데이터로 모형 추정 : y절편, 기울기 get.
print(fit_model.coef_) # 기울기 89.47430739
print(fit_model.intercept_) # y절편 100.0
# 예측값 확인 함수
y_pred2 = fit_model.predict(xx[[0]])
print('y_pred2 :', y_pred2)
y_pred2_new = fit_model.predict([[66]])
print('y_pred2_new :', y_pred2_new)
방법 3 : ols 사용. model O.
import statsmodels.formula.api as smf
import pandas as pd
x1 = xx.flatten() # 차원 축소
print(x1.shape)
y1 = yy
print(y1)
data = np.array([x1, y1])
df = pd.DataFrame(data.T)
df.columns = ['x1', 'y1']
print(df.head(3))
'''
x1 y1
0 -1.700736 -52.172143
1 -0.677945 39.341308
2 0.318665 128.512356
'''
model2 = smf.ols(formula='y1 ~ x1', data=df).fit()
print(model2.summary())
# 예측값 확인 함수
print(x1[:2]) # [-1.70073563 -0.67794537]
new_df = pd.DataFrame({'x1':[-1.70073563, -0.67794537]}) # 기존 자료로 검증
new_pred = model2.predict(new_df)
print('new_pred :\n', new_pred)
'''
new_pred :
0 -52.172143
1 39.341308
'''
new2_df = pd.DataFrame({'x1':[123, -2.34567]}) # 새로운 값에 대한 예측 결과 확인
new2_pred = model2.predict(new2_df)
print('new2_pred :\n', new2_pred)
'''
new2_pred :
0 11105.339809
1 -109.877199
'''
방법 4 : linregress 사용. model O
* liner_reg3.py
from scipy import stats
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
score_iq = pd.read_csv('../testdata/score_iq.csv')
print(score_iq.head(3))
'''
sid score iq academy game tv
0 10001 90 140 2 1 0
1 10002 75 125 1 3 3
2 10003 77 120 1 0 4
'''
print(score_iq.info())
# iq가 score에 영향을 주는 지 검정
# iq로 score(시험점수) 값 예측 - 정량적 분석
x = score_iq.iq
y = score_iq.score
# 상관계수
print(np.corrcoef(x, y)) # numpy 0.88222034
print(score_iq.corr()) # pandas 0.882220
# 두 변수는 인과 관계가 있다고 보고, 선형회귀 분석 진행.
model = stats.linregress(x, y)
print(model)
print('p-value :', model.pvalue) # p-value : 2.8476895206683644e-50
print('기울기 :', model.slope) # 기울기 : 0.6514309527270075
print('y절편 :', model.intercept) # y절편 : -2.8564471221974657
# pvalue=2.8476895206683644e-50 < 0.05 이므로 현재 모델은 유의하다.
# iq가 score에 영향을 준다.
# y = 0.6514309527270075 * x -2.8564471221974657
print('예측결과 :', 0.6514309527270075 * 140 -2.8564471221974657)
# 예측결과 : 88.34388625958358
print('예측결과 :', 0.6514309527270075 * 125 -2.8564471221974657)
# 예측결과 : 78.57242196867847
print('예측결과 :', 0.6514309527270075 * 80 -2.8564471221974657)
# 예측결과 : 49.25802909596313
print('예측결과 :', 0.6514309527270075 * 155 -2.8564471221974657)
# 예측결과 : 98.11535055048869
print('예측결과 :', model.slope * 155 + model.intercept)
# 예측결과 : 98.11535055048869# linregress는 predict()가 지원되지않음. numpy의 polyval 이용.
#print('예측결과 :', np.polyval([model.slope, model.intercept], np.array(score_iq['iq'])))
new_df = pd.DataFrame({'iq':[55, 66, 77, 88, 155]})
print('예측결과 :\n', np.polyval([model.slope, model.intercept], new_df))
'''
예측결과 :
[[32.97225528]
[40.13799576]
[47.30373624]
[54.46947672]
[98.11535055]]
'''np.polyval([기울기, y절편], data) : numpy predict함수
'BACK END > Deep Learning' 카테고리의 다른 글
| [딥러닝] 다항회귀 (0) | 2021.03.12 |
|---|---|
| [딥러닝] 단순선형 회귀, 다중선형 회귀 (0) | 2021.03.11 |
| [딥러닝] 공분산, 상관계수 (0) | 2021.03.10 |
| [딥러닝] 이항검정 (0) | 2021.03.10 |
| [딥러닝] ANOVA (0) | 2021.03.08 |