22. 비계층적 군집분석 : 군집수를 정해 주고 분석을 진행
: k-means가 가장 많이 쓰임
iris_s <- scale(iris[-5]) # scale : 표준화 함수를 이용. Species열은 제외
head(iris_s, 3)- 군집 개수 결정 후 k-means 모델 작성
install.packages("NbClust")
library(NbClust)
nc <- NbClust(iris_s, min.nc = 2, max.nc = 10, method="kmeans") # nc 클러스터 수
table(nc$Best.nc[1, ])
# 0 2 3 8 10
# 2 11 11 1 1
plot(table(nc$Best.nc[1, ]))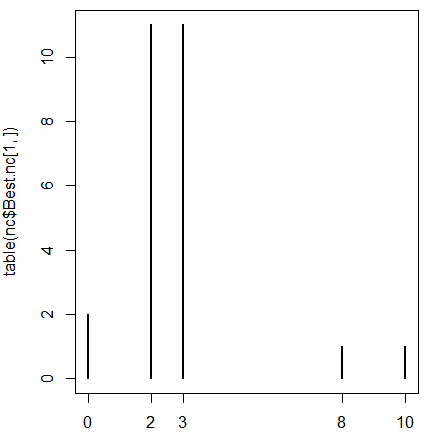
iris_k <- kmeans(iris_s, centers = 3, iter.max = 100)
iris_k
names(iris_k)
table(iris_k$cluster)
# 1 2 3
# 62 50 38
plot(iris_k$cluster, col=iris_k$cluster)
iris$Species2 <- ifelse(iris$Species == 'setosa', 1, iris$Species)
head(iris, 3)
plot(iris$Species2, col=iris$Species2)
- PAM
library(cluster)
iris_pam <- pam(iris_s, 3)
iris_pam
names(iris_pam)
(iris_pam$clustering)
table(iris_pam$clustering) # 교차 분할표
# 1 2 3
# 50 52 48
clusplot(iris_pam)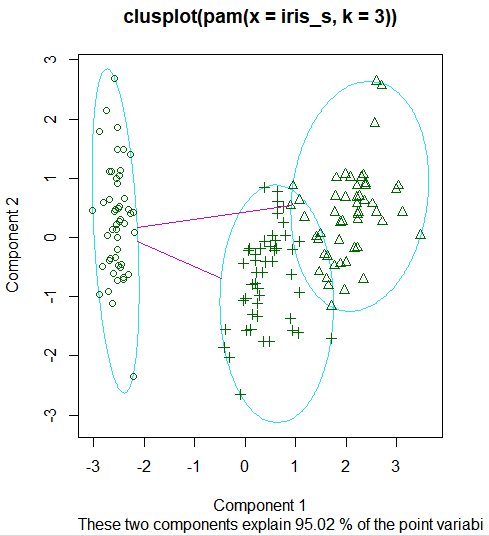
'BACK END > R' 카테고리의 다른 글
| [R] R 정리 24 - 연관분석 (0) | 2021.02.05 |
|---|---|
| [R] R 정리 23 - 비계층적 군집분석2 (k-means) (0) | 2021.02.05 |
| [R] R 정리 21 - 계층적 군집분석 (0) | 2021.02.04 |
| [R] R 정리 20 - MLP(deep learning) (0) | 2021.02.04 |
| [R] R 정리 19 - ANN(인공 신경망) (0) | 2021.02.03 |