T 검정
: 집단 간 평균(비율) 차이 검정
: 평균값의 차이와 표준편차의 비율이 얼마나 큰지 혹은 작은지 통계적으로 검정하는 방법
독립변수 : 범주형 => t-test(2개이하) / anova(3개이상)
종속변수 : 연속형
T 검정 종류
One sample t test
Indepenent t test
Paired t test
단일 표본 검정 (one sample t-test)
: 하나의 집단에 대한 표본평균이 예측된 평균과 같은지 여부를 검정하나의 집단에 대한 표본평균과 새롭게 수집된 데이터의 예측된 평균이 같은지 여부를 검정
실습 1 : 어느 남성 집단의 평균 키 검정
귀무가설 : 남성 집단의 평균 키가 177이다. 샘플의 평균과 모집단의 평균은 같다.
대립가설 : 남성 집단의 평균 키가 177아니다. 샘플의 평균과 모집단의 평균은 다르다.
* t1.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as stats
one_sample =[177.0, 182.7, 169.6, 176.8, 180.0]
print(np.array(one_sample).mean()) # 평균 : 177.21999999999997
one_sample2 =[167.0, 162.7, 169.6, 176.8, 170.0]
print(np.array(one_sample2).mean()) # 평균 : 169.21999999999997
result1 = stats.ttest_1samp(one_sample, popmean=177) # popmean : 모집단의 평균
print('result1 :', result1)
# result1 : Ttest_1sampResult(statistic=0.10039070766877535, pvalue=0.9248646407498543)p-value=0.92486 > 0.05 이므로 귀무가설 채택
# 귀무가설 : 남성 집단의 평균 키가 177이다. 샘플의 평균과 모집단의 평균은 같다.
result2 = stats.ttest_1samp(one_sample2, popmean=177)
print('result2 :', result2)
# result2 : Ttest_1sampResult(statistic=-3.3850411682038235, pvalue=0.02765632703927135)p-value=0.02765 < 0.05 이므로 귀무가설 기각
# 대립가설 : 남성 집단의 평균 키가 177아니다. 샘플의 평균과 모집단의 평균은 다르다.
result3 = stats.ttest_1samp(one_sample, popmean=165)
print('result3 :', result3)p-value=0.005 < 0.05 이므로 귀무가설 기각
# 대립가설 : 남성 집단의 평균 키가 177아니다. 샘플의 평균과 모집단의 평균은 다르다.
stats.ttest_1samp(데이터, popmean=모집단 평균) : one sample t-test 함수
실습 2 : 어느 집단 자료 평균 검정
귀무가설 : 자료들의 평균은 0이다.
대립가설 : 자료들의 평균은 0이 아니다.
np.random.seed(123)
mu = 0
n = 10
x = stats.norm(mu).rvs(n) # 평균이 0인 가우시안 정규분포를 따르는 난수 10개 출력
print(x)
#[-1.0856306 0.99734545 0.2829785 -1.50629471 -0.57860025 1.65143654 -2.42667924 -0.42891263 1.26593626 -0.8667404 ]
print(np.mean(x)) #-0.26951611032632805
import seaborn as sns
# x 데이터의 정규성 만족 여부 확인
sns.distplot(x, kde=False, fit=stats.norm) # 분포 시각화
plt.show()import seaborn as sns
sns.distplot(x, kde=, fit=) : 히스토그램

print(stats.shapiro(x)) # 정규성 검정 함수
# ShapiroResult(statistic=0.9674148559570312, pvalue=0.8658965229988098)p-value 0.865 > 0.05 이므로 정규성 만족
stats.shapiro(데이터) : 정규성 검정 함수
result4 = stats.ttest_1samp(x, popmean=0) # 모수의 평균 키
print('result4 :', result4)
# result4 : Ttest_1sampResult(statistic=-0.6540040368674593, pvalue=0.5294637946339893)p-value=0.529 > 0.05 이므로 귀무가설 채택
# 귀무가설 : 자료들의 평균은 0이다.
# 참고 : 모수의 평균이 0.8이라고 하면
result5 = stats.ttest_1samp(x, popmean=0.8) # 모수의 평균 키
print('result5 :', result5)
# result5 : Ttest_1sampResult(statistic=-2.595272886660806, pvalue=0.028961904737220684)p-value=0.028 < 0.05 이므로 귀무가설 채택
# 대립가설 : 자료들의 평균은 0이 아니다.
실습 3 : A 중학교 1 학년 1 반 학생들의 시험결과가 담긴 파일을 읽어 처리 (국어 점수 80점에 대한 평균검정)
귀무가설 : 학생들의 국어점수의 평균은 80이다.
대립가설 : 학생들의 국어점수의 평균은 80이 아니다.
* t2.py
import pandas as pd
import scipy.stats as stats
import numpy as np
data = pd.read_csv("../testdata/student.csv")
print(data.head(3))
'''
이름 국어 영어 수학
0 박치기 90 85 55
1 홍길동 70 65 80
2 김치국 92 95 76
'''
print(data.describe())
print(np.mean(data.국어)) # 72.9와 80은 평균에 차이가 있는지 확인.
print(stats.shapiro(data.국어))
result = stats.ttest_1samp(data.국어, popmean=80)
print('result :',result)pvalue=0.19 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 학생들의 국어점수의 평균은 80이다.
result2 = stats.ttest_1samp(data.국어, popmean=60)
print('result2 :',result2)pvalue=0.02568 < 0.05 이므로 귀무가설 기각.
# 대립가설 : 학생들의 국어점수의 평균은 80이 아니다.
실습4 : 여아 신생아 몸무게의 평균 검정 수행
여아 신생아의 몸무게는 평균이 2800(g) 으로 알려져 왔으나 이보다 더 크다는 주장이 나왔다.
표본으로 여아 18 명을 뽑아 체중을 측정하였다고 할 때 새로운 주장이 맞는지 검정해 보자
귀무가설 : 여아 신생아 몸무게의 평균이 2800g이다.
대립가설 : 여아 신생아 몸무게의 평균이 2800g 보다 크다.
data = pd.read_csv("https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/babyboom.csv")
print(data.head(3))
'''
time gender weight minutes
0 5 1 3837 5
1 104 1 3334 64
2 118 2 3554 78
'''
print(data.describe()) # gender - 1 : 여아, 2: 남아
fdata = data[data.gender == 1]
print(fdata.head(3), len(fdata), np.mean(fdata.weight))
'''
time gender weight minutes
0 5 1 3837 5
1 104 1 3334 64
5 405 1 2208 245
18명, 평균 : 3132.4444444444443
'''
# 3132(g)과 2800(g)에 대해 평균에 차이가 있는 지 검정.# 정규성 확인
# 통계 추론시 대부분이 모집단은 정규분포를 따른다는 가정하에 진행하는 것이 일반적이다. 중심 극한의 원리에 의해
# 중심 극한의 원리 : 표본의 크기가 커질 수록 표본 평균의 분포는 모집단의 분포 모양과는 관계없이 정규 분포에 가까워진다.
print(stats.shapiro(fdata.weight)) # p-value=0.0179 < 0.05 => 정규성 위반import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(fdata.iloc[:, 2], fit=stats.norm)
plt.show()
stats.probplot(fdata.iloc[:, 2], plot=plt) # Q-Q plot 상에서 정규성 확인 - 잔차의 정규성
plt.show()stats.probplot(데이터, plot=plt) : Q-Q plot 상에서 정규성 확인 - 잔차의 정규성

result3 = stats.ttest_1samp(fdata.weight, popmean=2800)
print('result3 :',result3) # pvalue=0.03926844173060218pvalue=0.0392 < 0.05 이므로 귀무가설 기각.
# 대립가설 : 여아 신생아 몸무게의 평균이 2800g 보다 크다.
서로 독립인 두 집단의 평균 차이 검정 (independent samples t test)
선행조건 : 두 집단은 정규분포를 따라야 하며, 두 집단의 분산이 동일해야한다.
남녀의 성적 A 반과 B 반의 키 경기도와 충청도의 소득 따위의 서로 독립인 두 집단에서 얻은 표본을 독립표본 (two sample) 이라고 한다

실습1 : 남녀 두 집단 간 파이썬 시험의 평균 차이 검정
귀무가설 : 남녀 두 집단 간 파이썬 시험의 평균에 차이가 없다.
대립가설 : 남녀 두 집단 간 파이썬 시험의 평균에 차이가 있다.
* t3.py
import numpy as np
import scipy.stats as stats
male= [75, 85, 100, 72.5, 86.5]
female = [63.2, 76, 52, 100, 70]
print(np.mean(male)) # 83.8
print(np.mean(female)) # 72.24
# 데이터에 대한 정규성/ 등분산성은 생략
two_sample = stats.ttest_ind(male, female)
two_sample = stats.ttest_ind(male, female, equal_var = True)
# equal_var=True(default): 등분산을 만족한 경우
print(two_sample.pvalue)
print(two_sample)
# Ttest_indResult(statistic=1.233193127514512, pvalue=0.25250768448532773)stats.ttest_ind(x, y, equal_var =) : 독립 샘플 t 검정
pvalue=0.2525 > 0.05 이므로 귀무채택.
# 귀무가설 : 남녀 두 집단 간 파이썬 시험의 평균에 차이가 없다.
실습2 : 두 가지 교육방법에 따른 평균시험 점수에 대한 검정 수행
귀무가설 : 두 가지 교육방법에 따른 평균시험 점수에 차이가 없다.
대립가설 : 두 가지 교육방법에 따른 평균시험 점수에 차이가 있다.
import pandas as pd
data = pd.read_csv('../testdata/two_sample.csv')
print(data.head(3))
'''
no gender method survey score
0 1 1 1 1 5.1
1 2 1 2 0 NaN
2 3 1 1 1 4.7
'''
ms = data[['method', 'score']]
print(data['method'].unique()) # [1 2]
# 교육방법 별로 데이터 분리
m1 = ms[ms['method'] == 1]
m2 = ms[ms['method'] == 2]
print(m1[:5])
'''
method score
0 1 5.1
2 1 4.7
4 1 5.4
7 1 5.2
10 1 5.7
'''
print(m2[:5])
'''
method score
1 2 NaN
3 2 NaN
5 2 4.4
6 2 4.9
8 2 4.3
'''sco1 = m1['score']
sco2 = m2['score']
# NaN : 임의의 값으로 대체, 평균으로 대체, 제거
#sco1 = sco1.fillna(0)
sco1 = sco1.fillna(sco1.mean())
sco2 = sco2.fillna(sco2.mean())
print()
print(sco1[:5])
'''
0 5.1
2 4.7
4 5.4
7 5.2
10 5.7
'''
print(sco2[:5])
'''
1 5.246667
3 5.246667
5 4.400000
6 4.900000
8 4.300000
'''fillna(대체값) : 결측치 임의의 값으로 대체.
- 정규성 확인
import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(sco1, kde = False, fit=stats.norm)
sns.distplot(sco2, kde = False, fit=stats.norm)
plt.show()
print(stats.shapiro(sco1)) # pvalue=0.3679 > 0.05 정규성 만족.
print(stats.shapiro(sco2)) # pvalue=0.6714 > 0.05
print(stats.levene(sco1, sco2)) # pvalue=0.4568 > 0.05 등분산성 만족
print(stats.fligner(sco1, sco2)) # pvalue=0.4432
print(stats.bartlett(sco1, sco2)) # 비모수 30개 이상. pvalue=0.2678
result = stats.ttest_ind(sco1, sco2, equal_var=True) # 정규성 만족, 등분산성 만족할 경우
print(result) # pvalue=0.8450stats.levene(x, y) : 등분산성 검증(레빈).
stats.fligner(x, y) : 등분산성 검증(플리그너).
stats.bartlett(x, y) : 등분산성 검증(바틀렛).
결론 : pvalue=0.8450 > 0.05 이므로 귀무채택.
# 귀무가설 : 두 가지 교육방법에 따른 평균시험 점수에 차이가 없다.
# 참고
result = stats.ttest_ind(sco1, sco2, equal_var=False) # 정규성 만족, 등분산성 만족하지 못할 경우
result = stats.wilcoxon(sco1, sco2)
print(result)
실습3 : 어느 음식점의 매출자료와 날씨 자료를 이용하여 강수여부에 따른 매출의 평균의 차이에 대한 검정
집단 1 : 비가 올때의 매출, 집단 2 : 비가 안올때의 매출
귀무가설 : 강수여부에 따른 매출액 평균에 차이가 없다.
대립가설 : 강수여부에 따른 매출액 평균에 차이가 있다.
* t4.py
- 매출자료
import numpy as np
import scipy.stats as stats
import pandas as pd
import matplotlib.pyplot as plt
sales_data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/tsales.csv', dtype={'YMD':'object'})
print(sales_data.head(3)) # 328행
'''
YMD AMT CNT
0 20190514 0 1
1 20190519 18000 1
2 20190521 50000 4
'''
print(sales_data.info())
- 날씨 자료
wt_data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/tweather.csv')
print(wt_data.head(3)) # 702행
'''
stnId tm avgTa minTa maxTa sumRn maxWs avgWs ddMes
0 108 2018-06-01 23.8 17.5 30.2 0.0 4.3 1.9 0.0
1 108 2018-06-02 23.4 17.6 30.1 0.0 4.5 2.0 0.0
2 108 2018-06-03 24.0 16.9 30.8 0.0 4.2 1.6 0.0
'''
print(wt_data.info())
- 날짜를 기준으로 join
wt_data.tm = wt_data.tm.map(lambda x : x.replace('-','')) # wt_data.tm에서 '-' 제거
#print(wt_data.head(3))
frame = sales_data.merge(wt_data, how='left', left_on='YMD', right_on='tm') # join
print(frame.head(3), frame.shape) # (328, 12)
'''
YMD AMT CNT stnId tm ... maxTa sumRn maxWs avgWs ddMes
0 20190514 0 1 108 20190514 ... 26.9 0.0 4.1 1.6 0.0
1 20190519 18000 1 108 20190519 ... 21.6 22.0 2.7 1.2 0.0
2 20190521 50000 4 108 20190521 ... 23.8 0.0 5.9 2.9 0.0
'''
print(frame.columns)df1.merge(df2, how='left', left_on='df1 칼럼', right_on='df2 칼럼') : join
- 분석에 참여할 칼럼만 추출
data = frame.iloc[:, [0,1,7,8]]
print(data.head(3))
'''
YMD AMT maxTa sumRn
0 20190514 0 26.9 0.0
1 20190519 18000 21.6 22.0
2 20190521 50000 23.8 0.0
'''
# 방법 1
print(data['sumRn'] > 0)
data['rain_yn'] = (data['sumRn'] > 0).astype(int)
print(data.head(3))
'''
YMD AMT maxTa sumRn rain_yn
0 20190514 0 26.9 0.0 0
1 20190519 18000 21.6 22.0 1
2 20190521 50000 23.8 0.0 0
'''
# 방법 2
print(True * 1, False * 1) # 1 0
data['rain_yn'] = (data.loc[:, ('sumRn')] > 0) * 1
print(data.head(3))df.astype(타입명) : 타입변경
- 강수여부에 따른 매출액 비교용 시각화
sp = np.array(data.iloc[:, [1, 4]]) # AMT, rain_yn
tg1 = sp[sp[:, 1] == 0, 0] # 비가 안올때의 매출액
tg2 = sp[sp[:, 1] == 1, 0] # 비가 올때의 매출액
print(tg1[:3]) # [ 0 50000 125000]
print(tg2[:3]) # [ 18000 274000 318000]
print(np.mean(tg1), np.mean(tg2)) # 761040.2542372881 757331.5217391305
plt.plot(tg1)
plt.show()
plt.plot(tg2)
plt.show()
plt.boxplot([tg1, tg2], meanline=True, showmeans=True, notch=True)
plt.show()plt.boxplot([data1, data2], meanline=True, showmeans=True, notch=True) : 상자 막대그래프
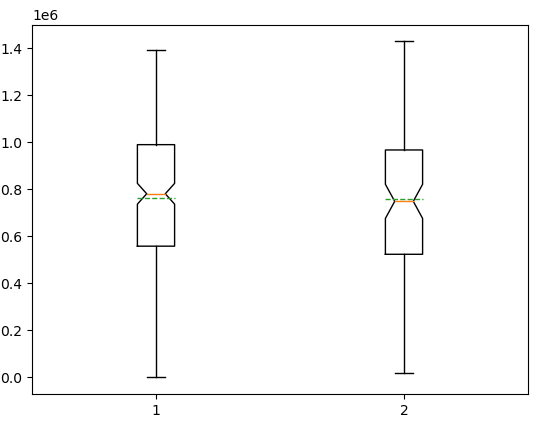
- 두 집단 평균차이 검정
# 정규성 (N > 30)
print(len(tg1), ' ', len(tg2)) # 236 92
print(stats.shapiro(tg1).pvalue) # 0.0560 > 0.05 => 정규성 만족
print(stats.shapiro(tg2).pvalue) # 0.8827
# 등분산
print(stats.levene(tg1, tg2).pvalue) # 0.7123 > 0.05 => 등분산성 만족
print(stats.ttest_ind(tg1, tg2, equal_var=True)) # pvalue=0.9195결론 : pvalue=0.9195 > 0.05 이므로 귀무가설 채택.
# 귀무가설 : 강수여부에 따른 매출액 평균에 차이가 없다.
서로 대응인 두 집단의 평균 차이 검정 (paired samples t test)
: 처리 이전과 처리 이후를 각각의 모집단으로 판단하여 동일한 관찰 대상으로부터 처리 이전과 처리 이후를 1:1 로 대응시킨 두 집단으로 부터의 표본을 대응표본 (paired sample) 이라고 한다.
: 대응인 두 집단의 평균 비교는 동일한 관찰 대상으로부터 처리 이전의 관찰과 이후의 관찰을 비교하여 영향을 미친 정도를 밝히는데 주로 사용하고 있다 집단 간 비교가 아니므로 등분산 검정을 할 필요가 없다.
: 광고 전/후의 상품 판매량의 차이, 운동 전/후의 근육량의 차이
실습 1 : 특강 전/후의 시험점수는 차이
귀무가설 : 특강 전/후의 시험점수는 차이가 없다.
대립가설 : 특강 전/후의 시험점수는 차이가 있다.
* t5.py
import numpy as np
import scipy.stats as stats
from seaborn.distributions import distplot
# 대응 표본 t 검정 1
np.random.seed(12)
x1 = np.random.normal(80, 10, 100)
x2 = np.random.normal(77, 10, 100)# 정규성
import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(x1, kde=False, fit=stats.norm)
sns.distplot(x2, kde=False, fit=stats.norm)
plt.show()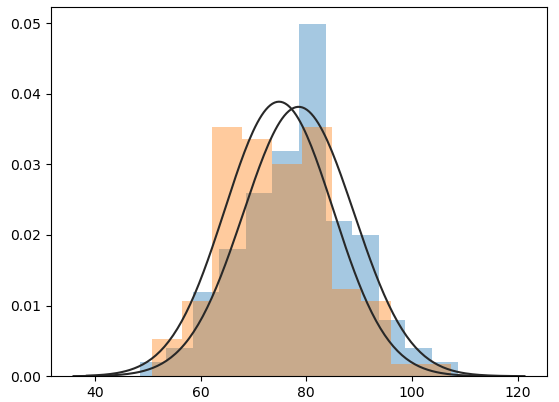
print(stats.shapiro(x1)) # pvalue=0.9942 > 0.05 => 정규성 만족
print(stats.shapiro(x2)) # pvalue=0.7985
# 집단이 하나이므로 등분산성 검즘은 하지않는다.
print(stats.ttest_rel(x1, x2))stats.ttest_rel(x1, x2) : 서로 대응인 두 집단의 평균 차이 검정
결론 : pvalue=0.0187 < 0.05 이므로 귀무가설 기각.
# 대립가설 : 특강 전/후의 시험점수는 차이가 있다.
실습 2 : 환자 9명의 복부 수술 전/후 몸무게 변화
귀무가설 : 복부 수술 전/후 몸무게 변화가 없다.
대립가설 : 복부 수술 전/후 몸무게 변화가 있다.
baseline = [67.2, 67.4, 71.5, 77.6, 86.0, 89.1, 59.5, 81.9, 105.5]
follow_up = [62.4, 64.6, 70.4, 62.6, 80.1, 73.2, 58.2, 71.0, 101.0]
print(np.mean(baseline)) # 78.41111111111111
print(np.mean(follow_up)) # 71.5
print(np.mean(baseline) - np.mean(follow_up)) # 6.911111111111111
result = stats.ttest_rel(baseline, follow_up)
print(result) pvalue=0.0063 < 0.05 => 귀무가설 기각.
# 대립가설 : 복부 수술 전/후 몸무게 변화가 있다.
'BACK END > Deep Learning' 카테고리의 다른 글
| [딥러닝] 선형회귀 (0) | 2021.03.10 |
|---|---|
| [딥러닝] 공분산, 상관계수 (0) | 2021.03.10 |
| [딥러닝] 이항검정 (0) | 2021.03.10 |
| [딥러닝] ANOVA (0) | 2021.03.08 |
| [딥러닝] 카이제곱 (0) | 2021.03.04 |