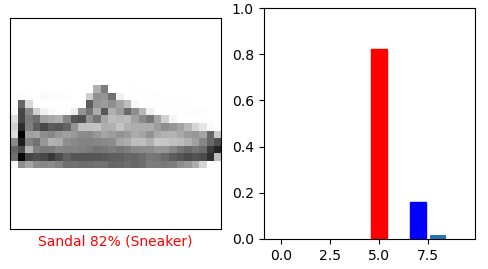
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout, BatchNormalization, Activation, LeakyReLU, UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import os
# token, corpus, vocabulary, one-hot, word2vec, tfidf,
from tensorflow.keras.preprocessing.text import Tokenizer
samples = ['The cat say on the mat.', 'The dog ate my homework.'] # list type
# token 처리 1 - word index
token_index = {}
for sam in samples:
for word in sam.split(sep=' '):
if word not in token_index:
#print(word)
token_index[word] = len(token_index)
print(token_index)
# {'The': 0, 'cat': 1, 'say': 2, 'on': 3, 'the': 4, 'mat.': 5, 'dog': 6, 'ate': 7, 'my': 8, 'homework.': 9}
print()
# token 처리 2 - word index
# tokenizer = Tokenizer(num_words=3) # num_words=3 빈도가 높은 3개의 토큰 만 작업에 참여
tokenizer = Tokenizer()
tokenizer.fit_on_texts(samples)
token_seq = tokenizer.texts_to_sequences(samples) # 문자열을 index로 표현
print(token_seq)
# [[1, 2, 3, 4, 1, 5], [1, 6, 7, 8, 9]]
print(tokenizer.word_index) # 특수 문자 제거 및 대문자를 소문자로 변환
# {'the': 1, 'cat': 2, 'say': 3, 'on': 4, 'mat': 5, 'dog': 6, 'ate': 7, 'my': 8, 'homework': 9}
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.text import Tokenizer
text = """운동장에 눈이 많이 쌓여 있다
그 사람의 눈이 빛난다
맑은 눈이 사람 마음을 곱게 만든다"""
tok = Tokenizer()
tok.fit_on_texts([text])
encoded = tok.texts_to_sequences([text])
print(encoded)
# [[2, 1, 3, 4, 5, 6, 7, 1, 8, 9, 1, 10, 11, 12, 13]]
print(tok.word_index)
# {'눈이': 1, '운동장에': 2, '많이': 3, '쌓여': 4, '있다': 5, '그': 6, '사람의': 7, '빛난다': 8, '맑은': 9, '사람': 10, '마음을': 11, '곱게': 12, '만든다': 13}
vocab_size = len(tok.word_index) + 1
print('단어 집합의 크기 :%d'%vocab_size)
# 단어 집합의 크기 :14
import numpy as np
import random, sys
import tensorflow as tf
f = open("rnn_test_toji.txt", 'r', encoding="utf-8")
text = f.read()
#print(text)
f.close();
print('텍스트 행 수: ', len(text)) # 306967
print(set(text)) # set 집합형 함수를 이용해 중복 제거{'얻', '턴', '옮', '쩐', '제', '평',...
chars = sorted(list(set(text))) # 중복이 제거된 문자를 하나하나 읽어 들여 정렬
print(chars) # ['\n', ' ', '!', ... , '0', '1', ... 'a', 'c', 'f', '...
print('사용되고 있는 문자 수:', len(chars)) # 1469
char_indices = dict((c, i) for i, c in enumerate(chars)) # 문자와 ID
indices_char = dict((i, c) for i, c in enumerate(chars)) # ID와 문자
print(char_indices) # ... '것': 106, '겄': 107, '겅': 108,...
print(indices_char) # ... 106: '것', 107: '겄', 108: '겅',...
# 텍스트를 maxlen개의 문자로 자르고 다음에 오는 문자 등록하기
maxlen = 20
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
#print(text[i: i + maxlen])
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('학습할 구문 수:', len(sentences)) # 102316
print('텍스트를 ID 벡터로 변환')
X = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
print(X[:3])
print(y[:3])
for i, sent in enumerate(sentences):
#print(sent)
for t, char in enumerate(sent):
#print(t, ' ', char)
X[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
print(X[:5]) # 찾은 글자에만 True, 나머지는 False 기억
print(y[:5])
# 모델 구축하기(LSTM(RNN의 개량종)) -------------
# 하나의 LSTM 층과 그 뒤에 Dense 분류층 추가
model = tf.keras.Sequential()
model.add(tf.keras.layers.LSTM(128, activation='tanh', input_shape=(maxlen, len(chars))))
model.add(tf.keras.layers.Dense(128))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(len(chars)))
model.add(tf.keras.layers.Activation('softmax'))
opti = tf.keras.optimizers.Adam(lr=0.001)
model.compile(loss='categorical_crossentropy', optimizer=opti, metrics=['acc'])
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(patience = 5, monitor='loss')
model.fit(X, y, epochs=500, batch_size=64, verbose=2, callbacks=[es])
print(model.evaluate(X, y))
# 확률적 샘플링 처리 함수(무작위적으로 샘플링하기 위함)
# 모델의 예측이 주어졌을 때 새로운 글자를 샘플링
def sample_func(preds, variety=1.0): # 후보를 배열에서 꺼내기
# array():복사본, asarray():참조본 생성 - 원본 변경시 복사본은 변경X 참조본은 변경O
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / variety # 로그확률 벡터식을 코딩
exp_preds = np.exp(preds) # 자연상수 얻기
preds = exp_preds / np.sum(exp_preds) # softmax 공식 참조
probas = np.random.multinomial(1, preds, 1) # 다항식분포로 샘플 얻기
return np.argmax(probas)
for num in range(1, 2): # 학습시키고 텍스트 생성하기 반복 1, 60
print()
print('--' * 30)
print('반복 =', num)
# 데이터에서 한 번만 반복해서 모델 학습
model.fit(X, y, batch_size=128, epochs=1, verbose=0)
# 임의의 시작 텍스트 선택하기
start_index = random.randint(0, len(text) - maxlen - 1)
for variety in [0.2, 0.5, 1.0, 1.2]: # 다양한 문장 생성
print('\n--- 다양성 = ', variety) # 다양성 = 0.2 -> 다양성 = 0.5 -> ...
generated = ''
sentence = text[start_index: start_index + maxlen]
generated += sentence
print('--- 시드 = "' + sentence + '"') # --- 시드 = "께 간뎅이가 부어서, 시부릴기력 있거"...
sys.stdout.write(generated)
# 시드를 기반으로 텍스트 자동 생성. 시드 텍스트에서 시작해서 500개의 글자를 생성
for i in range(500):
x = np.zeros((1, maxlen, len(chars))) # 지금까지 생성된 글자를 원핫인코딩 처리
for t, char in enumerate(sentence):
x[0, t, char_indices[char]] = 1.
# 다음에 올 문자를 예측하기(다음 글자를 샘플링)
preds = model.predict(x, verbose=0)[0]
next_index = sample_func(preds, variety) # 다양한 문장 생성을 위함
next_char = indices_char[next_index]
# 출력하기
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
print(df['headline'].head())
# 0 Former N.F.L. Cheerleaders’ Settlement Offer: ...
# 1 E.P.A. to Unveil a New Rule. Its Effect: Less ...
# 2 The New Noma, Explained
# 3 Unknown
# 4 Unknown
print(df.headline.values)
# ['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell'
# 'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.'
# 'The New Noma, Explained' ...
# 'Gen. Michael Hayden Has One Regret: Russia'
# 'There Is Nothin’ Like a Tune' 'Unknown']
headline = []
headline.extend(list(df.headline.values))
print(headline[:10])
# ['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
# 'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.', 'The New Noma, Explained', 'Unknown', 'Unknown', 'Unknown', 'Unknown', 'Unknown', 'How a Bag of Texas Dirt Became a Times Tradition', 'Is School a Place for Self-Expression?']
# Unknown 값은 노이즈로 판단해 제거
print(len(headline)) # 1324
headline = [n for n in headline if n != 'Unknown']
print(len(headline)) # 1214
# 구굿점 제거, 소문자 처리
print('He하이llo 가a나b123다'.encode('ascii', errors="ignore").decode()) # Hello ab123
from string import punctuation
print(", python.'".strip(punctuation)) # python
print(", py thon.'".strip(punctuation + ' ')) # py thon
#-------------------------------------------------------------------
def repre_func(s):
s = s.encode('utf8').decode('ascii', 'ignore')
return ''.join(c for c in s if c not in punctuation).lower()
text = [repre_func(s) for s in headline]
print(text[:10])
# ['former nfl cheerleaders settlement offer 1 and a meeting with goodell', 'epa to unveil a new rule its effect less science in policymaking', 'the new noma explained', 'how a bag of texas dirt became a times tradition', 'is school a place for selfexpression', 'commuter reprogramming', 'ford changed leaders looking for a lift its still looking', 'romney failed to win at utah convention but few believe hes doomed', 'chain reaction', 'he forced the vatican to investigate sex abuse now hes meeting with pope francis']
from tensorflow.keras.layers import Embedding, Dense, LSTM
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Embedding(vocab_size, 32, input_length = max_len -1))
model.add(LSTM(128, activation='tanh'))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x, y, epochs=50, verbose=2, batch_size=32)
print(model.evaluate(x, y))
# [1.3969029188156128, 0.7689350247383118]
def sentence_gen(model, t, current_word, n):
init_word = current_word
sentence = ''
for _ in range(n):
encoded = t.texts_to_sequences([current_word])[0]
encoded = pad_sequences([encoded], maxlen = max_len - 1, padding = 'pre')
result = np.argmax(model.predict(encoded))
# print(result)
for word, index in t.word_index.items():
#print('word:', word, ', index:', index)
if index == result:
break
current_word = current_word + ' ' + word
sentence = sentence + ' ' + word # 예측단어를 문장에 저장
sentence = init_word + sentence
return sentence
print(sentence_gen(model, tok, 'i', 10))
print(sentence_gen(model, tok, 'how', 10))
print(sentence_gen(model, tok, 'how', 100))
print(sentence_gen(model, tok, 'good', 200))
print(sentence_gen(model, tok, 'python', 10))
# i brain injuries are tied to dementia abuse him slippery crashes
# how to serve a deranged tyrant stoically a pope fields for
# how to serve a deranged tyrant stoically a pope fields for a cathedral todo meet in a cathedral strike president apply for her police in privatized scientists about fast denmark says shot was life according at 92 was michael whims of webs and comey memoir too life aids still alive too african life on still loss to exfbi chief in new york lifts renewable sources to doing apply at 92 for say he police at pope francis say it was was too aids to behind was back to 92 was back to type not too common beach reimaginedjurassic african apartheid on
# good calls off trip to latin america citing crisis in syria not to invade back at meeting from pope francis doomed it recalls it was back to be focus of them to comey francis say risk risk it recalls about it us potent tolerance of others or products slippery leak of journalist it just hes aids hes risk it comey francis rude it was back to was not too was was rude francis it was endorse rival endorse rude was still alive 1738 african was shot him didnt him didnt it was endorse rival too was was it was endorse rival too rude apply to them to comey he officials to back to smiles at pope francis say it recalls it was back on not from uk officials of not 2002 not too pope francis too was too doomed francis not trying to them war uk officials say lawyers apply to agreement from muppets children say been mainstream it us border architect of misconduct to not francis it was say to invade endorse rival was behind apply to agreement on nafta children about gay draws near to director for north korea us children pledges recalls it was too rude francis risk
# python to men pushed to the edge investigation syria trump about
자연어 생성 글자 단위, 단어단위, 자소 단위
자연어 생성 : 단어 단위 생성
* tf_rnn8_토지_단어단위.ipynb
# 토지 또는 조선왕조실록 데이터 파일 다운로드
# https://github.com/wikibook/tf2/blob/master/Chapter7.ipynb
import tensorflow as tf
import numpy as np
path_to_file = tf.keras.utils.get_file('toji.txt', 'https://raw.githubusercontent.com/pykwon/etc/master/rnn_test_toji.txt')
#path_to_file = 'silrok.txt'
# 데이터 로드 및 확인. encoding 형식으로 utf-8 을 지정해야합니다.
train_text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# 텍스트가 총 몇 자인지 확인합니다.
print('Length of text: {} characters'.format(len(train_text))) # Length of text: 695685 characters
# 처음 100 자를 확인해봅니다.
print(train_text[:100])
# 제 1 편 어둠의 발소리
# 1897년의 한가위.
# 까치들이 울타리 안 감나무에 와서 아침 인사를 하기도 전에, 무색 옷에 댕기꼬리를 늘인
# 아이들은 송편을 입에 물고 마을길을 쏘
# 훈련 데이터 입력 정제
import re
# From https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
def clean_str(string):
string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", "", string)
string = re.sub(r"\)", "", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\'{2,}", "\'", string)
string = re.sub(r"\'", "", string)
return string
train_text = train_text.split('\n')
train_text = [clean_str(sentence) for sentence in train_text]
train_text_X = []
for sentence in train_text:
train_text_X.extend(sentence.split(' '))
train_text_X.append('\n')
train_text_X = [word for word in train_text_X if word != '']
print(train_text_X[:20])
# ['제', '1', '편', '어둠의', '발소리', '\n', '1897년의', '한가위', '\n', '까치들이', '울타리', '안', '감나무에', '와서', '아침', '인사를', '하기도', '전에', ',', '무색']
# 단어 토큰화
# 단어의 set을 만듭니다.
vocab = sorted(set(train_text_X))
vocab.append('UNK') # 텍스트 안에 존재하지 않는 토큰을 나타내는 'UNK' 사용
print ('{} unique words'.format(len(vocab)))
# vocab list를 숫자로 맵핑하고, 반대도 실행합니다.
word2idx = {u:i for i, u in enumerate(vocab)}
idx2word = np.array(vocab)
text_as_int = np.array([word2idx[c] for c in train_text_X])
# word2idx 의 일부를 알아보기 쉽게 print 해봅니다.
print('{')
for word,_ in zip(word2idx, range(10)):
print(' {:4s}: {:3d},'.format(repr(word), word2idx[word]))
print(' ...\n}')
print('index of UNK: {}'.format(word2idx['UNK']))
# 토큰 데이터 확인. 20개만 확인
print(train_text_X[:20])
print(text_as_int[:20])
# 기본 데이터셋 만들기
seq_length = 25 # 25개의 단어가 주어질 경우 다음 단어를 예측하도록 데이터를 만듦
examples_per_epoch = len(text_as_int) // seq_length
sentence_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
# seq_length + 1 은 처음 25개 단어와 그 뒤에 나오는 정답이 될 1 단어를 합쳐 함께 반환하기 위함
# drop_remainder=True 남는 부분은 제거 속성
sentence_dataset = sentence_dataset.batch(seq_length + 1, drop_remainder=True)
for item in sentence_dataset.take(1):
print(idx2word[item.numpy()])
print(item.numpy())
# 학습 데이터셋 만들기
# 26개의 단어가 각각 입력과 정답으로 묶어서 ([25단어], 1단어) 형태의 데이터를 반환하기 위한 작업
def split_input_target(chunk):
return [chunk[:-1], chunk[-1]]
train_dataset = sentence_dataset.map(split_input_target)
for x,y in train_dataset.take(1):
print(idx2word[x.numpy()])
print(x.numpy())
print(idx2word[y.numpy()])
print(y.numpy())
# 데이터셋 shuffle, batch 설정
BATCH_SIZE = 64
steps_per_epoch = examples_per_epoch // BATCH_SIZE
BUFFER_SIZE = 5000
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
# 단어 단위 생성 모델 정의
total_words = len(vocab)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(total_words, 100, input_length=seq_length),
tf.keras.layers.LSTM(units=100, return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(units=100),
tf.keras.layers.Dense(total_words, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
# 단어 단위 생성 모델 학습
from tensorflow.keras.preprocessing.sequence import pad_sequences
def testmodel(epoch, logs):
if epoch % 5 != 0 and epoch != 49:
return
test_sentence = train_text[0]
next_words = 100
for _ in range(next_words):
test_text_X = test_sentence.split(' ')[-seq_length:]
test_text_X = np.array([word2idx[c] if c in word2idx else word2idx['UNK'] for c in test_text_X])
test_text_X = pad_sequences([test_text_X], maxlen=seq_length, padding='pre', value=word2idx['UNK'])
output_idx = model.predict_classes(test_text_X)
test_sentence += ' ' + idx2word[output_idx[0]]
print()
print(test_sentence)
print()
# 모델을 학습시키며 모델이 생성한 결과물을 확인하기 위해 LambdaCallback 함수 생성
testmodelcb = tf.keras.callbacks.LambdaCallback(on_epoch_end=testmodel)
history = model.fit(train_dataset.repeat(), epochs=50,
steps_per_epoch=steps_per_epoch,
callbacks=[testmodelcb], verbose=2)
model.save('rnnmodel.hdf5')
del model
from tensorflow.keras.models import load_model
model=load_model('rnnmodel.hdf5')
# 임의의 문장을 사용한 생성 결과 확인
test_sentence = '최참판댁 사랑은 무인지경처럼 적막하다'
#test_sentence = '동헌에 나가 공무를 본 후 활 십오 순을 쏘았다'
next_words = 500
for _ in range(next_words):
# 임의 문장 입력 후 뒤에서 부터 seq_length 만킁ㅁ의 단어(25개) 선택
test_text_X = test_sentence.split(' ')[-seq_length:]
# 문장의 단어를 인덱스 토큰으로 바꿈. 사전에 등록되지 않은 경우에는 'UNK' 코큰값으로 변경
test_text_X = np.array([word2idx[c] if c in word2idx else word2idx['UNK'] for c in test_text_X])
# 문장의 앞쪽에 빈자리가 있을 경우 25개 단어가 채워지도록 패딩
test_text_X = pad_sequences([test_text_X], maxlen=seq_length, padding='pre', value=word2idx['UNK'])
# 출력 중에서 가장 값이 큰 인덱스 반환
output_idx = model.predict_classes(test_text_X)
test_sentence += ' ' + idx2word[output_idx[0]] # 출력단어는 test_sentence에 누적해 다음 스테의 입력으로 활용
print(test_sentence)
# LambdaCallback
# keras에서 여러가지 상황에서 콜백이되는 class들이 만들어져 있는데, LambdaCallback 등의 Callback class들은
# 기본적으로 keras.callbacks.Callback class를 상속받아서 특정 상황마다 콜백되는 메소드들을 재정의하여 사용합니다.
# LambdaCallback는 lambda 평션을 작성하여 생성자에 넘기는 방식으로 사용 할 수 있습니다.
# callback 시 받는 arg는 Callbakc class에 정의 되어 있는대로 맞춰 주어야 합니다.
# on_epoch_end메소드로 정의하여 epoch이 끝날 때 마다 확인해보도록 하겠습니다.
# 아래 처럼 lambda 함수를 작성하여 LambdaCallback를 만들어 주고, 이때 epoch, logs는 신경 안쓰시고 arg 형태만 맞춰주면 됩니다.
# from keras.callbacks import LambdaCallback
# print_weights = LambdaCallback(on_epoch_end=lambda epoch, logs: print(model.layers[3].get_weights()))
!pip install jamotools
import tensorflow as tf
import numpy as np
import jamotools
path_to_file = tf.keras.utils.get_file('toji.txt', 'https://raw.githubusercontent.com/pykwon/etc/master/rnn_test_toji.txt')
#path_to_file = 'silrok.txt'
# 데이터 로드 및 확인. encoding 형식으로 utf-8 을 지정해야합니다.
train_text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# 텍스트가 총 몇 자인지 확인합니다.
print('Length of text: {} characters'.format(len(train_text))) # Length of text: 695685 characters
print()
# 처음 100 자를 확인해봅니다.
s = train_text[:100]
print(s)
# 한글 텍스트를 자모 단위로 분리해줍니다. 한자 등에는 영향이 없습니다.
s_split = jamotools.split_syllables(s)
print(s_split)
Length of text: 695685 characters
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아침 인사를 하기도 전에, 무색 옷에 댕기꼬리를 늘인
아이들은 송편을 입에 물고 마을길을 쏘
ㅈㅔ 1 ㅍㅕㄴ ㅇㅓㄷㅜㅁㅇㅢ ㅂㅏㄹㅅㅗㄹㅣ
1897ㄴㅕㄴㅇㅢ ㅎㅏㄴㄱㅏㅇㅟ.
ㄲㅏㅊㅣㄷㅡㄹㅇㅣ ㅇㅜㄹㅌㅏㄹㅣ ㅇㅏㄴ ㄱㅏㅁㄴㅏㅁㅜㅇㅔ ㅇㅘㅅㅓ ㅇㅏㅊㅣㅁ ㅇㅣㄴㅅㅏㄹㅡㄹ ㅎㅏㄱㅣㄷㅗ ㅈㅓㄴㅇㅔ, ㅁㅜㅅㅐㄱ ㅇㅗㅅㅇㅔ ㄷㅐㅇㄱㅣㄲㅗㄹㅣㄹㅡㄹ ㄴㅡㄹㅇㅣㄴ
ㅇㅏㅇㅣㄷㅡㄹㅇㅡㄴ ㅅㅗㅇㅍㅕㄴㅇㅡㄹ ㅇㅣㅂㅇㅔ ㅁㅜㄹㄱㅗ ㅁㅏㅇㅡㄹㄱㅣㄹㅇㅡㄹ ㅆㅗ
import jamotools
jamotools.split_syllables(s) :
# 7.45 자모 결합 테스트
s2 = jamotools.join_jamos(s_split)
print(s2)
print(s == s2)
# 7.46 자모 토큰화
# 텍스트를 자모 단위로 나눕니다. 데이터가 크기 때문에 약간 시간이 걸립니다.
train_text_X = jamotools.split_syllables(train_text)
vocab = sorted(set(train_text_X))
vocab.append('UNK')
print ('{} unique characters'.format(len(vocab))) # 179 unique characters
# vocab list를 숫자로 맵핑하고, 반대도 실행합니다.
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in train_text_X])
print(text_as_int) # [69 81 2 ... 2 1 0]
# word2idx 의 일부를 알아보기 쉽게 print 해봅니다.
print('{')
for char,_ in zip(char2idx, range(10)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...\n}')
print('index of UNK: {}'.format(char2idx['UNK']))
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아침 인사를 하기도 전에, 무색 옷에 댕기꼬리를 늘인
아이들은 송편을 입에 물고 마을길을 쏘
True
179 unique characters
[69 81 2 ... 2 1 0]
{
'\n': 0,
'\r': 1,
' ' : 2,
'!' : 3,
'"' : 4,
"'" : 5,
'(' : 6,
')' : 7,
',' : 8,
'-' : 9,
...
}
index of UNK: 178
# 7.49 자소 단위 생성 모델 정의
total_chars = len(vocab)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(total_chars, 100, input_length=seq_length),
tf.keras.layers.LSTM(units=400, activation='tanh'),
tf.keras.layers.Dense(total_chars, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary() # Total params: 891,279
# 7.50 자소 단위 생성 모델 학습
from tensorflow.keras.preprocessing.sequence import pad_sequences
def testmodel(epoch, logs):
if epoch % 5 != 0 and epoch != 99:
return
test_sentence = train_text[:48]
test_sentence = jamotools.split_syllables(test_sentence)
next_chars = 300
for _ in range(next_chars):
test_text_X = test_sentence[-seq_length:]
test_text_X = np.array([char2idx[c] if c in char2idx else char2idx['UNK'] for c in test_text_X])
test_text_X = pad_sequences([test_text_X], maxlen=seq_length, padding='pre', value=char2idx['UNK'])
output_idx = model.predict_classes(test_text_X)
test_sentence += idx2char[output_idx[0]]
print()
print(jamotools.join_jamos(test_sentence))
print()
testmodelcb = tf.keras.callbacks.LambdaCallback(on_epoch_end=testmodel)
history = model.fit(train_dataset.repeat(), epochs=50, steps_per_epoch=steps_per_epoch, \
callbacks=[testmodelcb], verbose=2)
Epoch 1/50
262/262 - 37s - loss: 2.9122 - accuracy: 0.2075
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/sequential.py:450: UserWarning: `model.predict_classes()` is deprecated and will be removed after 2021-01-01. Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
warnings.warn('`model.predict_classes()` is deprecated and '
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 안이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알이이 알잉
Epoch 2/50
262/262 - 7s - loss: 2.3712 - accuracy: 0.3002
Epoch 3/50
262/262 - 7s - loss: 2.2434 - accuracy: 0.3256
Epoch 4/50
262/262 - 7s - loss: 2.1652 - accuracy: 0.3414
Epoch 5/50
262/262 - 7s - loss: 2.1132 - accuracy: 0.3491
Epoch 6/50
262/262 - 7s - loss: 2.0670 - accuracy: 0.3600
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 았다. "아난 강이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는 갈이는
Epoch 7/50
262/262 - 7s - loss: 2.0299 - accuracy: 0.3709
Epoch 8/50
262/262 - 7s - loss: 1.9852 - accuracy: 0.3810
Epoch 9/50
262/262 - 7s - loss: 1.9415 - accuracy: 0.3978
Epoch 10/50
262/262 - 7s - loss: 1.9119 - accuracy: 0.4020
Epoch 11/50
262/262 - 7s - loss: 1.8684 - accuracy: 0.4153
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니라고 날 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 ㄱ
Epoch 12/50
262/262 - 7s - loss: 1.8237 - accuracy: 0.4272
Epoch 13/50
262/262 - 7s - loss: 1.7745 - accuracy: 0.4429
Epoch 14/50
262/262 - 7s - loss: 1.7272 - accuracy: 0.4625
Epoch 15/50
262/262 - 7s - loss: 1.6779 - accuracy: 0.4688
Epoch 16/50
262/262 - 7s - loss: 1.6217 - accuracy: 0.4902
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 안 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 간 가
Epoch 17/50
262/262 - 7s - loss: 1.5658 - accuracy: 0.5041
Epoch 18/50
262/262 - 7s - loss: 1.4984 - accuracy: 0.5252
Epoch 19/50
262/262 - 7s - loss: 1.4413 - accuracy: 0.5443
Epoch 20/50
262/262 - 7s - loss: 1.3629 - accuracy: 0.5704
Epoch 21/50
262/262 - 7s - loss: 1.2936 - accuracy: 0.5923
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"아는 말이 잡아낙에 사람 가나가 가라. 가나구가 가람 가나고. 사남이 바람이 그렇게 없는 노루가 가나가오. 아니라."
"아는 말이 잡아낙에 사람 가나가 가라. 가나구가 가람 가나고. 사남이 바람이 그렇게 없는 노루가 가나가오. 아니라."
"아는 말이 잡아낙에 사람 가나가 ㄱ
Epoch 22/50
262/262 - 7s - loss: 1.2142 - accuracy: 0.6217
Epoch 23/50
262/262 - 7s - loss: 1.1281 - accuracy: 0.6505
Epoch 24/50
262/262 - 7s - loss: 1.0444 - accuracy: 0.6786
Epoch 25/50
262/262 - 7s - loss: 0.9711 - accuracy: 0.7047
Epoch 26/50
262/262 - 7s - loss: 0.8712 - accuracy: 0.7445
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"예, 서방이 타람 자기 있는 놀을 벤 앙이는 곡서방을 마지 않았다. 장모수는 잠 밀 앞은 알 앞은 것이다. 그러나 속으로 나랑치를 그렇더면 정을 비한 것은 알굴이 말고 마른 안 부리 전 물어지를 하는 것이다. 그런 소릴 긴데 없는 갈아조 말 앞은 ㅇ
Epoch 27/50
262/262 - 7s - loss: 0.8168 - accuracy: 0.7620
Epoch 28/50
262/262 - 7s - loss: 0.7244 - accuracy: 0.7985
Epoch 29/50
262/262 - 7s - loss: 0.6301 - accuracy: 0.8362
Epoch 30/50
262/262 - 7s - loss: 0.5399 - accuracy: 0.8695
Epoch 31/50
262/262 - 7s - loss: 0.4745 - accuracy: 0.8950
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"그건 치신하게 소기일이고 나랑치가 가래 참아노려 하고 사람을 딸려들 하더나건서반다.
"줄에 나무장 다과 있는데 마을 세나강이 사이오. 나익은 노영은 물을 딸로나 잉인이의 얼굴이 없고 바람을 들었다. 그 천덕이 속을 거밀렀다. 지녁해지직 때 났는데 이 ㅇ
Epoch 32/50
262/262 - 7s - loss: 0.3956 - accuracy: 0.9234
Epoch 33/50
262/262 - 7s - loss: 0.3326 - accuracy: 0.9429
Epoch 34/50
262/262 - 7s - loss: 0.2787 - accuracy: 0.9577
Epoch 35/50
262/262 - 7s - loss: 0.2249 - accuracy: 0.9738
Epoch 36/50
262/262 - 7s - loss: 0.1822 - accuracy: 0.9837
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"그래 갱째기를 하였던 것이다. 그러나 소습으로 있을 물었다. 가나게, 한장한다.
"안 빌리 장에서 나였다. 체신기린 조한 시릴 세에 있이는 노랭이 되었다. 나무지 족은 야우는 물을 만다. 울씨는 지소 가라! 담하는 누눌이 말씨갔다.
"일서 좀은 이융이의 ㄴ
Epoch 37/50
262/262 - 7s - loss: 0.1399 - accuracy: 0.9902
Epoch 38/50
262/262 - 7s - loss: 0.1123 - accuracy: 0.9942
Epoch 39/50
262/262 - 7s - loss: 0.0864 - accuracy: 0.9968
Epoch 40/50
262/262 - 7s - loss: 0.0713 - accuracy: 0.9979
Epoch 41/50
262/262 - 7s - loss: 0.0552 - accuracy: 0.9989
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"전을 짐 집 갚고 불랑이 떳어지는 닷마닥네서 쑤어직 때 가자. 다동이 타타자그마."
"전을 지작한고, 그런 세닉을 바들 가는고 마진 오를 기는 불림이 최치른다. 한 일을 물었다.
"눈저 살아노, 흔자하는 나루에."
"저는 물을 물어져들 자몬 아니요."
Epoch 42/50
262/262 - 7s - loss: 0.0431 - accuracy: 0.9994
Epoch 43/50
262/262 - 7s - loss: 0.0325 - accuracy: 0.9998
Epoch 44/50
262/262 - 7s - loss: 0.2960 - accuracy: 0.9110
Epoch 45/50
262/262 - 7s - loss: 0.1939 - accuracy: 0.9540
Epoch 46/50
262/262 - 7s - loss: 0.0542 - accuracy: 0.9979
제 1 편 어둠의 발소리
1897년의 한가위.
까치들이 울타리 안 감나무에 와서 아니요."
"전을 떰은 탕첫
은 안나무네."
"그건 심심해 사람을 놀었다. 음....간 들지 휜 오를
까끄치올을 쓸어얐다. 베여 갈인 덧못이야. 그건 시김이 잡아나게 생가가지가 다라고들 하고 사람들 색했으면 조신 소리를 필징이 갔다. 체공인 든장은 무소 그러핬다
Epoch 47/50
262/262 - 7s - loss: 0.0265 - accuracy: 0.9999
Epoch 48/50
262/262 - 7s - loss: 0.0189 - accuracy: 1.0000
Epoch 49/50
262/262 - 7s - loss: 0.0156 - accuracy: 1.0000
Epoch 50/50
262/262 - 7s - loss: 0.0131 - accuracy: 1.0000
model.save('rnnmodel2.hdf5')
# 7.51 임의의 문장을 사용한 생성 결과 확인
from tensorflow.keras.preprocessing.sequence import pad_sequences
test_sentence = '최참판댁 사랑은 무인지경처럼 적막하다'
test_sentence = jamotools.split_syllables(test_sentence)
next_chars = 5000
for _ in range(next_chars):
test_text_X = test_sentence[-seq_length:]
test_text_X = np.array([char2idx[c] if c in char2idx else char2idx['UNK'] for c in test_text_X])
test_text_X = pad_sequences([test_text_X], maxlen=seq_length, padding='pre', value=char2idx['UNK'])
output_idx = model.predict_classes(test_text_X)
test_sentence += idx2char[output_idx[0]]
print(jamotools.join_jamos(test_sentence))
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/sequential.py:450: UserWarning: `model.predict_classes()` is deprecated and will be removed after 2021-01-01. Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
warnings.warn('`model.predict_classes()` is deprecated and '
최참판댁 사랑은 무인지경처럼 적막하다가 최차는 야우는 물을 물었다.
"내가 적에서 이자사 아니요."
"전을 떰은 안 불이라 강천 갓촉을 농해 났이 마으러서 같은 노웅이 것을 치문이 참만난 함잉이의 송순이라 강을 덜걱을 눈치를 최철었다.
"오를 놀짝은 노영은 뭇
이들을 달려들 도만 살알이 되었다. 나무지 족은 야움을 놀을 허렸다. 그건 신기를 물을 달려들 딸을 동렸다.
“선으로 바람 사람을 바습으로 나왔다.
간가나게, 사람들 사람을 했는 노래원이 머를 세 있는 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰집은 것 같았다.
강산이 족은 양피는 가날이 아니요."
"예, 산고 가탕이 다시 죽얼 지 구천하게 그러세 얼굴을 달련 덧을 부칠리 질 없는 농은 언분네요."
"그건 소리가 아니물이 용닌이 되수 성을 흠금글고 달려가지 아나갔다.
"그러나 내간이고 내발이 탂어서 달려가지 않나. 무고 고랭각은 다사 죽어러들어지 않았다.
간곡이얐다. 지낙해지 안 가기요."
"잔은 안 불린 것 같았다.
강산이 종굴이 왔고 싶은 상모수는 곳한 곰지
RNN을 이용한 스펨메일 분류(이진 분류)
* tf_rnn10_스팸메일분류.ipynb
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/spam.csv', encoding='latin1')
print(data.head())
print('샘플 수 : ', len(data)) # 샘플 수 : 5572
del data['Unnamed: 2']
del data['Unnamed: 3']
del data['Unnamed: 4']
print(data.head())
# v1 ... Unnamed: 4
# 0 ham ... NaN
# 1 ham ... NaN
# 2 spam ... NaN
# 3 ham ... NaN
# 4 ham ... NaN
print(data.v1.unique()) # ['ham' 'spam']
data['v1'] = data['v1'].replace(['ham', 'spam'], [0, 1])
print(data.head())
# Null 여부 확인
print(data.isnull().values.any()) # False
print(data.info())
# 중복 데이터 확인
print(data['v2'].nunique()) # 5169
data.drop_duplicates(subset=['v2'], inplace=True)
print('중복 데이터 제거 후 샘플 수 : ', len(data)) # 5169
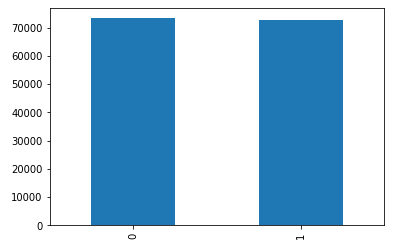
print(data.groupby('v1').size().reset_index(name='count'))
# v1 count
# 0 0 4516
# 1 1 653
# feature(v2), label(v1) 분리
xdata = data['v2']
ydata = data['v1']
print(xdata[:3])
# 0 Go until jurong point, crazy.. Available only ...
# 1 Ok lar... Joking wif u oni...
# 2 Free entry in 2 a wkly comp to win FA Cup fina...
print(ydata[:3])
# 0 0
# 1 0
# 2 1
- token 처리
from tensorflow.keras.preprocessing.text import Tokenizer
tok = Tokenizer()
tok.fit_on_texts(xdata)
print(tok.word_index) # {'i': 1, 'to': 2, 'you': 3, 'a': 4, 'the': 5, 'u': 6, 'and': 7, 'in': 8, 'is': 9, 'me': 10 ...
sequences = tok.texts_to_sequences(xdata)
print(xdata[:5])
# 0 Go until jurong point, crazy.. Available only ...
# 1 Ok lar... Joking wif u oni...
# 2 Free entry in 2 a wkly comp to win FA Cup fina...
# 3 U dun say so early hor... U c already then say...
# 4 Nah I don't think he goes to usf, he lives aro...
print(sequences[:5])
# [[47, 433, 4013, 780, 705, 662, 64, 8, 1202, 94, 121, 434, 1203, ...
word_index = tok.word_index
print(word_index)
# {'i': 1, 'to': 2, 'you': 3, 'a': 4, 'the': 5, 'u': 6, 'and': 7, 'in': 8, 'is': 9, 'me': 10, ...
print(len(word_index)) # 8920
# 전체 자료 중 등장빈도 수, 비율 확인
threshold = 2 # 등장빈도 수를 제한
total_count = len(word_index) # 전체 단어 수
rare_count = 0 # 빈도 수가 threshold 보다 작은 경우
total_freq = 0 # 전체 단어 빈도 수 총합 비율
rare_freq = 0 # 빈도 수 가 threshold보다 작은 경우의 단어 빈도 수 총합 비율 전체 자료 중 등장빈도 수, 비율 확인
threshold = 2 # 등장빈도 수를 제한
total_count = len(word_index) # 전체 단어 수
rare_count = 0 # 빈도 수가 threshold 보다 작은 경우
total_freq = 0 # 전체 단어 빈도 수 총합 비율
rare_freq = 0 # 빈도 수 가 threshold보다 작은 경우의 단어 빈도 수 총합 비율
# dict type의 단어/빈도수 얻기
for key, value in tok.word_counts.items():
#print('k:{} va:{}'.format(key, value))
# k:jd va:1
# k:accounts va:1
# k:executive va:2
# k:parents' va:2
# k:picked va:7
# k:downstem va:1
# k:08718730555 va:
total_freq = total_freq + value
if value < threshold:
rare_count = rare_count + 1
rare_freq = rare_freq + value
print('등장빈도가 1회인 단어 수 :', rare_count) # 등장빈도가 1회인 단어 수 : 4908
print('등장빈도가 1회인 단어 비율 :', (rare_count / total_count) * 100) # 등장빈도가 1회인 단어 비율 : 55.02242152466368
print('전체 중 등장빈도가 1회인 단어 비율 :', (rare_freq / total_freq) * 100) # 전체 중 등장빈도가 1회인 단어 비율 : 6.082538108811501
tok = Tokenizer(num_words= total_count - rare_count + 1)
vocab_size = len(word_index) + 1
print('단어 집합 크기 :', vocab_size) # 단어 집합 크기 : 8921
# train/test 8:2
n_of_train = int(len(sequences) * 0.8)
n_of_test = int(len(sequences) - n_of_train)
print('train lenghth :', n_of_train) # train lenghth : 4135
print('test lenghth :', n_of_test) # test lenghth : 1034
# 메일의 길이 확인
x_data = sequences
print('메일의 최대 길이 :', max((len(i) for i in x_data))) # 메일의 최대 길이 : 189
print('메일의 평균 길이 :', (sum(map(len, x_data)) / len(x_data))) # 메일의 평균 길이 : 15.610369510543626
# 시각화
import matplotlib.pyplot as plt
plt.hist([len(siz) for siz in x_data], bins=50)
plt.xlabel('length')
plt.ylabel('count')
plt.show()
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len = max((len(i) for i in x_data))
data = pad_sequences(x_data, maxlen=max_len)
print(data.shape) # (5169, 189)
# train/test 분리
import numpy as np
x_train = data[:n_of_train]
y_train = np.array(ydata[:n_of_train])
x_test = data[n_of_train:]
y_test = np.array(ydata[n_of_train:])
print(x_train.shape, x_train[:2]) # (4135, 189)
print(y_train.shape, y_train[:2]) # (4135,)
print(x_test.shape, y_test.shape) # (1034, 189) (1034,)
# 모델
from tensorflow.keras.layers import LSTM, Embedding, Dense, Dropout
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Embedding(vocab_size, 32))
model.add(LSTM(32, activation='tanh'))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
print(model.summary()) # Total params: 294,881
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
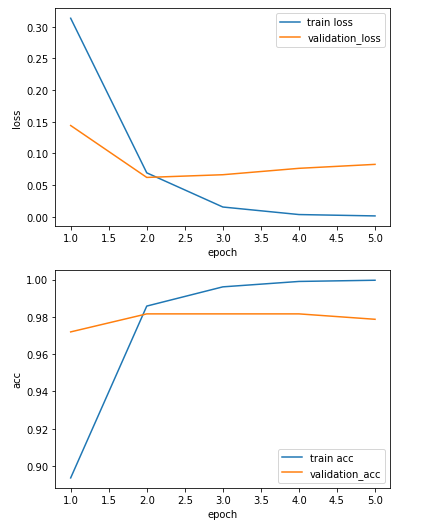
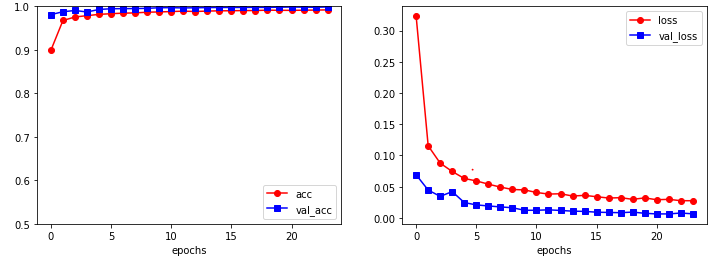
history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.25, verbose=2)
print('loss, acc :', model.evaluate(x_test, y_test)) # loss, acc : [0.05419406294822693, 0.9893617033958435]
# print(x_test[0])
word_index = reuters.get_word_index()
print(word_index) # {'mdbl': 10996, 'fawc': 16260, 'degussa': 12089, 'woods': 8803, 'hanging': 13796, ... }
index_to_word = {}
for k, v in word_index.items():
index_to_word[v] = k
print(index_to_word) # {10996: 'mdbl', 16260: 'fawc', 12089: 'degussa', 8803: 'woods', 13796: 'hanging ... }
print(index_to_word[1]) # the
print(index_to_word[10]) # for
print(index_to_word[100]) # group
print(x_train[0]) # [1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 2, 111, 16, 369, ...
print(' '.join(index_to_word[i] for i in x_train[0])) # he of of mln loss for plc said at only ended said of ...
len_result = [len(s) for s in x_train]
print('리뷰 최대 길이 :', np.max(len_result)) # 2494
print('리뷰 평균 길이 :', np.mean(len_result)) # 238.71364
plt.subplot(1, 2, 1)
plt.boxplot(len_result)
plt.subplot(1, 2, 2)
plt.hist(len_result, bins=50)
plt.show()
word_to_index = imdb.get_word_index()
index_to_word = {}
for k, v in word_to_index.items():
index_to_word[v] = k
print(index_to_word) # {34701: 'fawn', 52006: 'tsukino', 52007: 'nunnery', 16816: 'sonja', ...
print(index_to_word[1]) # the
print(index_to_word[1408]) # woods
print(x_train[0]) # [1, 14, 22, 16, 43, 530, 973, 1622, ...
print(y_train[0]) # 1
print(' '.join([index_to_word[index] for index in x_train[0]])) # the as you with out themselves powerful lets loves their ...
from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D, MaxPooling1D, Dropout
model = Sequential()
model.add(Embedding(vocab_size, 256))
model.add(Conv1D(256, kernel_size=3, padding='valid', activation='relu', strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
print(model.summary()) # Total params: 2,757,121
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
es = EarlyStopping(monitor='val_loss', mode='auto', patience=3, baseline=0.01)
ms = ModelCheckpoint('tfrmm12_1.h5', monitor='val_acc', mode='max', save_best_only = True)
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=100, batch_size=64, verbose=2, callbacks=[es, ms])
loaded_model = load_model('tfrmm12_1.h5')
print('acc :',loaded_model.evaluate(x_test, y_test)[1]) # acc : 0.8984400033950806
print('loss :',loaded_model.evaluate(x_test, y_test)[0]) # loss : 0.24771703779697418
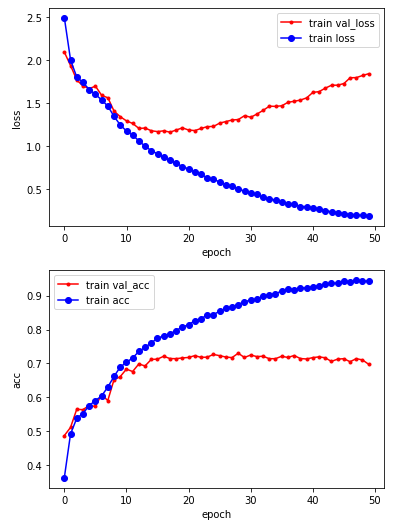
- 시각화
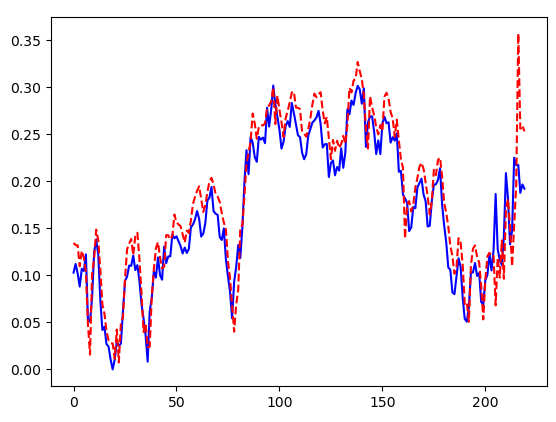
vloss = history.history['val_loss']
loss = history.history['loss']
x_len = np.arange(len(loss))
plt.plot(x_len, vloss, marker='+', c='black', label='val_loss')
plt.plot(x_len, loss, marker='s', c='red', label='loss')
plt.legend()
plt.grid()
plt.show()
import re
def sentiment_predict(new_sentence):
new_sentence = re.sub('[^0-9a-zA-Z ]', '', new_sentence).lower()
# 정수 인코딩
encoded = []
for word in new_sentence.split():
# 단어 집합의 크기를 10,000으로 제한.
try :
if word_to_index[word] <= 10000:
encoded.append(word_to_index[word]+3)
else:
encoded.append(2) # 10,000 이상의 숫자는 <unk> 토큰으로 취급.
except KeyError:
encoded.append(2) # 단어 집합에 없는 단어는 <unk> 토큰으로 취급.
pad_new = pad_sequences([encoded], maxlen = max_len) # 패딩
# 예측하기
score = float(loaded_model.predict(pad_new))
if(score > 0.5):
print("{:.2f}% 확률로 긍정!.".format(score * 100))
else:
print("{:.2f}% 확률로 부정!".format((1 - score) * 100))
# 99.57% 확률로 긍정!.
# 53.55% 확률로 긍정!.
# 긍/부정 분류 예측
#temp_str = "This movie was just way too overrated. The fighting was not professional and in slow motion."
temp_str = "This movie was a very touching movie."
sentiment_predict(temp_str)
temp_str = " I was lucky enough to be included in the group to see the advanced screening in Melbourne on the 15th of April, 2012. And, firstly, I need to say a big thank-you to Disney and Marvel Studios."
sentiment_predict(temp_str)
#! pip install konlpy
import numpy as np
import pandas as pd
import matplotlib as plt
import re
from konlpy.tag import Okt
from tensorflow.keras.layers import Embedding, Dense, LSTM, Dropout
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
drop_train = [index for index, sen in enumerate(x_train) if len(sen) < 1]
x_train = np.delete(x_train, drop_train, axis = 0)
y_train = np.delete(y_train, drop_train, axis = 0)
print(len(x_train), ' ', len(y_train))
print('리뷰 최대 길이 :', max(len(i) for i in x_train)) # 75
print('리뷰 평균 길이 :', sum(map(len, x_train)) / len(x_train)) # 12.169516185172293
plt.hist([len(s) for s in x_train], bins = 50)
plt.show()
- 전체 샘플 중에서 길이가 max_len 이하인 샘플 비율이 몇 % 인지 확인 함수 작성
- IMDB 리뷰 데이터로 감성 분류 : LSTM + Attension (Transformer 기반 기술)
* tf_rnn15_attention.ipynb
# IMDB 리뷰 데이터로 감성 분류 : LSTM + Attension (Transformer 기반 기술)
# 양방향 LSTM과 어텐션 메커니즘(BiLSTM with Attention mechanism)
from tensorflow.keras.datasets import imdb
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.sequence import pad_sequences
vocab_size = 10000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = vocab_size)
print('리뷰의 최대 길이 : {}'.format(max(len(l) for l in X_train))) # 리뷰의 최대 길이 : 2494
print('리뷰의 평균 길이 : {}'.format(sum(map(len, X_train))/len(X_train))) # 리뷰의 평균 길이 : 238.71364
max_len = 500
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
...
fig = plt.figure(figsize=(15, 3))
fig.subplots_adjust(hspace = 0.4, wspace = 0.4)
for i, idx in enumerate(range(len(x_test[:10]))):
img = x_test[idx]
ax = fig.add_subplot(1, len(x_test[:10]), i+1)
ax.axis('off')
ax.text(0.5, -0.35, 'pred=' + str(pred_single[idx]),\
fontsize=10, ha = 'center', transform = ax.transAxes)
ax.text(0.5, -0.7, 'actual=' + str(actual_single[idx]),\
fontsize=10, ha = 'center', transform = ax.transAxes)
ax.imshow(img)
plt.show()
- CNN + DENSE 레이어로만 분류작업2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input, Flatten, Dense, Conv2D, Activation, BatchNormalization, ReLU, LeakyReLU, MaxPool2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import cifar10
input_layer = Input(shape=(32,32,3))
x = Conv2D(filters=64, kernel_size=3, strides=2, padding='same')(input_layer)
x = MaxPool2D(pool_size=(2,2))(x)
#x = ReLU(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, kernel_size=3, strides=2, padding='same')(x)
x = MaxPool2D(pool_size=(2,2))(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Flatten()(x)
x = Dense(512)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Dense(128)(x)
x = BatchNormalization()(x)
x = LeakyReLU()(x)
x = Dense(NUM_CLASSES)(x)
output_layer = Activation('softmax')(x)
model = Model(input_layer, output_layer)
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
import numpy as np
import matplotlib.pyplot as plt
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats') # directory with our training cat pictures
train_dogs_dir = os.path.join(train_dir, 'dogs') # directory with our training dog pictures
validation_cats_dir = os.path.join(validation_dir, 'cats') # directory with our validation cat pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs') # directory with our validation dog pictures
- 이미지를 확인
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
# num_cats_te = len(os.listdir(test_cats_dir))
# num_dogs_te = len(os.listdir(test_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr
total_val = num_cats_val + num_dogs_val
# total_te = num_cats_te + num_dogs_te
print('total training cat images:', num_cats_tr)
print('total training dog images:', num_dogs_tr)
# print('total test dog images:', total_te)
# total training cat images: 1000
# total training dog images: 1000
print('total validation cat images:', num_cats_val)
print('total validation dog images:', num_dogs_val)
# total validation cat images: 500
# total validation dog images: 500
print("--")
print("Total training images:", total_train)
print("Total validation images:", total_val)
# Total training images: 2000
# Total validation images: 1000
- ImageDataGenerator
train_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our training data
validation_image_generator = ImageDataGenerator(rescale=1./255) # Generator for our validation data
train_data_gen = train_image_generator.flow_from_directory(batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(batch_size=batch_size,
directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary')
4. 데이터 확인
sample_training_images, _ = next(train_data_gen)
# This function will plot images in the form of a grid with 1 row and 5 columns where images are placed in each column.
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20,20))
axes = axes.flatten()
for img, ax in zip( images_arr, axes):
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()
plotImages(sample_training_images[:5])
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True)
train_data_gen = image_gen.flow_from_directory(batch_size=batch_size,
directory=train_dir,shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH))
augmented_images = [train_data_gen[0][0][0] for i in range(5)]
# Re-use the same custom plotting f
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True)
train_data_gen = image_gen.flow_from_directory(batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH))
augmented_images = [train_data_gen[0][0][0] for i in range(5)]
# Re-use the same custom plotting function defined and used
# above to visualize the training images
plotImages(augmented_images)
전부 적용
image_gen_train = ImageDataGenerator(
rescale=1./255,
rotation_range=45,
width_shift_range=.15,
height_shift_range=.15,
horizontal_flip=True,
zoom_range=0.5
)
train_data_gen = image_gen_train.flow_from_directory(batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='binary')
augmented_images = [train_data_gen[0][0][0] for i in range(5)]
plotImages(augmented_images)
! ls -al
! pip install tensorflow-datasets
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
전이 학습 파이 튜닝 : 미리 학습된 ConvNet의 마지막 FC Layer만 변경해 분류 실행
이전 학습의 모바일넷을 동경시키고 새로 추가한 레이어만 학습 (베이스 모델의 후방 레이어 일부만 다시 학습)
먼저 베이스 모델을 동결한 후 학습 진행 -> 학습이 끝나면 동결 해제
base_model.trainable = True
print('베이스 모델의 레이어 :', len(base_model.layers)) # 베이스 모델의 레이어 : 154
fine_tune_at = 100
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
import tensorflow.compat.v1 as tf # tf2.x 환경에서 1.x 소스 실행 시
tf.disable_v2_behavior() # tf2.x 환경에서 1.x 소스 실행 시
x_data = [[1,2],[2,3],[3,4],[4,3],[3,2],[2,1]]
y_data = [[0],[0],[0],[1],[1],[1]]
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 2])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([2, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W)))
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
# 로지스틱 회귀에서 Cost function 구하기
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))
# Optimizer(코스트 함수의 최소값을 찾는 알고리즘) 구하기
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
cost_val, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, cost_val)
# Accuracy report (정확도 출력)
h, c, a = sess.run([hypothesis, predicted, accuracy],feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a)
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior() : 텐서플로우 2환경에서 1 소스 실행 시 사용
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
np.random.seed(0)
x = np.array([[1,2],[2,3],[3,4],[4,3],[3,2],[2,1]])
y = np.array([[0],[0],[0],[1],[1],[1]])
model = Sequential([
Dense(units = 1, input_dim=2), # input_shape=(2,)
Activation('sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x, y, epochs=1000, batch_size=1, verbose=1)
meval = model.evaluate(x,y)
print(meval) # [0.209698(loss), 1.0(정확도)]
pred = model.predict(np.array([[1,2],[10,5]]))
print('예측 결과 : ', pred) # [[0.16490099] [0.9996613 ]]
print('예측 결과 : ', np.squeeze(np.where(pred > 0.5, 1, 0))) # [0 1]
for i in pred:
print(1 if i > 0.5 else print(0))
print([1 if i > 0.5 else 0 for i in pred])
# 2. function API 사용
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
inputs = Input(shape=(2,))
outputs = Dense(1, activation='sigmoid')
model2 = Model(inputs, outputs)
model2.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model2.fit(x, y, epochs=500, batch_size=1, verbose=0)
meval2 = model2.evaluate(x,y)
print(meval2) # [0.209698(loss), 1.0(정확도)]
# 과적합 방지 - train/test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=12)
print(x_train.shape, x_test.shape, y_train.shape) # (4547, 12) (1950, 12) (4547,)
# model
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(tf.keras.layers.BatchNormalization()) # 배치정규화. 그래디언트 손실과 폭주 문제 개선
model.add(Dense(15, activation='relu'))
model.add(tf.keras.layers.BatchNormalization()) # 배치정규화. 그래디언트 손실과 폭주 문제 개선
model.add(Dense(8, activation='relu'))
model.add(tf.keras.layers.BatchNormalization()) # 배치정규화. 그래디언트 손실과 폭주 문제 개선
model.add(Dense(1, activation='sigmoid'))
print(model.summary()) # Total params: 992
# 학습 설정
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 평가
loss, acc = model.evaluate(x_train, y_train, verbose=2)
print('훈련되지않은 모델의 분류 정확도 :{:5.2f}%'.format(100 * acc)) # 훈련되지않은 모델의 평가 :25.14%
model.add(tf.keras.layers.BatchNormalization()) : 배치정규화. 그래디언트 손실과 폭주 문제 개선
# 모델 저장 및 폴더 설정
import os
MODEL_DIR = './model/'
if not os.path.exists(MODEL_DIR): # 폴더가 없으면 생성
os.mkdir(MODEL_DIR)
# 모델 저장조건 설정
modelPath = "model/{epoch:02d}-{loss:4f}.hdf5"
# 모델 학습 시 모니터링의 결과를 파일로 저장
chkpoint = ModelCheckpoint(filepath='./model/abc.hdf5', monitor='loss', save_best_only=True)
#chkpoint = ModelCheckpoint(filepath=modelPath, monitor='loss', save_best_only=True)
# 학습 조기 종료
early_stop = EarlyStopping(monitor='loss', patience=5)
# 훈련
# 과적합 방지 - validation_split
history = model.fit(x_train, y_train, epochs=10000, batch_size=64,\
validation_split=0.3, callbacks=[early_stop, chkpoint])
model.load_weights('./model/abc.hdf5')
from tensorflow.keras.callbacks import ModelCheckpoint
checkkpoint = ModelCheckpoint(filepath=경로, monitor='loss', save_best_only=True) : 모델 학습 시 모니터링의 결과를 파일로 저장
from tensorflow.keras.callbacks import EarlyStopping
early_stop = EarlyStopping(monitor='loss', patience=5) : 학습 조기 종료
model.fit(x, y, epochs=, batch_size=, validation_split=, callbacks=[early_stop, checkpoint])
'''
여기에서는 인터넷 영화 데이터베이스(Internet Movie Database)에서 수집한 50,000개의 영화 리뷰 텍스트를 담은
IMDB 데이터셋을 사용하겠습니다. 25,000개 리뷰는 훈련용으로, 25,000개는 테스트용으로 나뉘어져 있습니다.
훈련 세트와 테스트 세트의 클래스는 균형이 잡혀 있습니다. 즉 긍정적인 리뷰와 부정적인 리뷰의 개수가 동일합니다.
매개변수 num_words=10000은 훈련 데이터에서 가장 많이 등장하는 상위 10,000개의 단어를 선택합니다.
데이터 크기를 적당하게 유지하기 위해 드물에 등장하는 단어는 제외하겠습니다.
'''
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0]) # 각 숫자는 사전에 있는 전체 문서에 나타난 모든 단어에 고유한 번호를 부여한 어휘사전
# [1, 14, 22, 16, 43, 530, 973, ...
print(train_labels) # 긍정 1 부정0
# [1 0 0 ... 0 1 0]
aa = []
for seq in train_data:
#print(max(seq))
aa.append(max(seq))
print(max(aa), len(aa))
# 9999 25000
word_index = imdb.get_word_index() # 단어와 정수 인덱스를 매핑한 딕셔너리
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decord_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print(decord_review)
# ? this film was just brilliant casting location scenery story direction ...
from tensorflow.keras import models, layers, regularizers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, ), kernel_regularizer=regularizers.l2(0.01)))
# regularizers.l2(0.001) : 가중치 행렬의 모든 원소를 제곱하고 0.001을 곱하여 네트워크의 전체 손실에 더해진다는 의미, 이 규제(패널티)는 훈련할 때만 추가됨
model.add(layers.Dropout(0.3)) # 과적합 방지를 목적으로 노드 일부는 학습에 참여하지 않음
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
print(model.summary())
layers.Dropout(n) : 과적합 방지를 목적으로 노드 일부는 학습에 참여하지 않음
from tensorflow.keras import models, layers, regularizers
x_train, x_test, y_train, y_test = train_test_split(x_scaler, y, test_size=0.3, random_state=1)
n_features = x_train.shape[1] # 열
n_classes = y_train.shape[1] # 열
print(n_features, n_classes) # 4 3 => input, output수
- n의 개수 만큼 모델 생성 함수
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def create_custom_model(input_dim, output_dim, out_node, n, model_name='model'):
def create_model():
model = Sequential(name = model_name)
for _ in range(n): # layer 생성
model.add(Dense(out_node, input_dim = input_dim, activation='relu'))
model.add(Dense(output_dim, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
return model
return create_model # 주소 반환(클로저)
models = [create_custom_model(n_features, n_classes, 10, n, 'model_{}'.format(n)) for n in range(1, 4)]
# layer수가 2 ~ 5개 인 모델 생성
for create_model in models:
print('-------------------------')
create_model().summary()
# Total params: 83
# Total params: 193
# Total params: 303
- train
history_dict = {}
for create_model in models: # 각 모델 loss, acc 출력
model = create_model()
print('Model names :', model.name)
# 훈련
history = model.fit(x_train, y_train, batch_size=5, epochs=50, verbose=0, validation_split=0.3)
# 평가
score = model.evaluate(x_test, y_test)
print('test dataset loss', score[0])
print('test dataset acc', score[1])
history_dict[model.name] = [history, model]
print(history_dict)
# {'model_1': [<tensorflow.python.keras.callbacks.History object at 0x00000273BA4E7280>, <tensorflow.python.keras.engine.sequential.Sequential object at 0x00000273B9B22A90>], ...}
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.xlabel(class_names[train_labels[i]])
plt.imshow(train_image[i])
plt.show()
model.save('ke21.h5')
model = tf.keras.models.load_model('ke21.h5')
import pickle
histoy = histoy.history # loss, acc
with open('data.pickle', 'wb') as f: # 파일 저장
pickle.dump(histoy) # 객체 저장
with open('data.pickle', 'rb') as f: # 파일 읽기
history = pickle.load(f) # 객체 읽기
import matplotlib.pyplot as plt
def plot_acc(title = None):
plt.plot(history['accuracy'])
plt.plot(history['val_accuracy'])
if title is not None:
plt.title(title)
plt.ylabel(title)
plt.xlabel('epoch')
plt.legend(['train data', 'validation data'], loc = 0)
plot_acc('accuracy')
plt.show()
def plot_loss(title = None):
plt.plot(history['loss'])
plt.plot(history['val_loss'])
if title is not None:
plt.title(title)
plt.ylabel(title)
plt.xlabel('epoch')
plt.legend(['train data', 'validation data'], loc = 0)
plot_loss('loss')
plt.show()
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import matplotlib.pyplot as plt
import numpy as np
import sys
import tensorflow as tf
import numpy as np
print(tf.keras.__version__)
1. 데이터 수집 및 가공
x = np.array([[0,0],[0,1],[1,0],[1,1]])
#y = np.array([0,1,1,1]) # or
#y = np.array([0,0,0,1]) # and
y = np.array([0,1,1,0]) # xor : node가 1인 경우 처리 불가
2. 모델 생성(네트워크 구성)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model = Sequential([
Dense(input_dim =2, units=1),
Activation('sigmoid')
])
model = Sequential()
model.add(Dense(units=1, input_dim=2))
model.add(Activation('sigmoid'))
# input_dim : 입력층의 뉴런 수
# units : 출력 뉴런 수
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
# 완벽한 모델이라 판단되면 모델을 저장
model.save('test.hdf5')
del model # 모델 삭제
from tensorflow.keras.models import load_model
model2 = load_model('test.hdf5')
pred2 = (model2.predict(x) > 0.5).astype('int32')
print('pred2 :\n', pred2.flatten())
model.save('파일명.hdf5') : 모델 삭제
del model : 모델 삭제
from tensorflow.keras.models import load_model model = load_model('파일명.hdf5') : 모델 불러오기
논리 게이트 XOR 해결을 위해 Node 추가
* ke2.py
import tensorflow as tf
import numpy as np
# 1. 데이터 수집 및 가공
x = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([0,1,1,0]) # xor : node가 1인 경우 처리 불가
# 단순 선형회귀 예측 모형 작성
# x = 5일 때 f(x) = 50에 가까워지는 w 값 찾기
import tensorflow as tf
import numpy as np
x = tf.Variable(5.0)
w = tf.Variable(0.0)
@tf.function
def train_step():
with tf.GradientTape() as tape: # 자동 미분을 위한 API 제공
#print(tape.watch(w))
y = tf.multiply(w, x) + 0
loss = tf.square(tf.subtract(y, 50)) # (예상값 - 실제값)의 제곱
grad = tape.gradient(loss, w) # 자동 미분
mu = 0.01 # 학습율
w.assign_sub(mu * grad)
return loss
for i in range(10):
loss = train_step()
print('{:1}, w:{:4.3}, loss:{:4.5}'.format(i, w.numpy(), loss.numpy()))
'''
0, w: 5.0, loss:2500.0
1, w: 7.5, loss:625.0
2, w:8.75, loss:156.25
3, w:9.38, loss:39.062
4, w:9.69, loss:9.7656
5, w:9.84, loss:2.4414
6, w:9.92, loss:0.61035
7, w:9.96, loss:0.15259
8, w:9.98, loss:0.038147
9, w:9.99, loss:0.0095367
'''
tf.GradientTape() :
gradient(loss, w) : 자동미분
# 옵티마이저 객체 사용
opti = tf.keras.optimizers.SGD()
x = tf.Variable(5.0)
w = tf.Variable(0.0)
@tf.function
def train_step2():
with tf.GradientTape() as tape: # 자동 미분을 위한 API 제공
y = tf.multiply(w, x) + 0
loss = tf.square(tf.subtract(y, 50)) # (예상값 - 실제값)의 제곱
grad = tape.gradient(loss, w) # 자동 미분
opti.apply_gradients([(grad, w)])
return loss
for i in range(10):
loss = train_step2()
print('{:1}, w:{:4.3}, loss:{:4.5}'.format(i, w.numpy(), loss.numpy()))
opti = tf.keras.optimizers.SGD() :
opti.apply_gradients([(grad, w)]) :
# 최적의 기울기, y절편 구하기
opti = tf.keras.optimizers.SGD()
x = tf.Variable(5.0)
w = tf.Variable(0.0)
b = tf.Variable(0.0)
@tf.function
def train_step3():
with tf.GradientTape() as tape: # 자동 미분을 위한 API 제공
#y = tf.multiply(w, x) + b
y = tf.add(tf.multiply(w, x), b)
loss = tf.square(tf.subtract(y, 50)) # (예상값 - 실제값)의 제곱
grad = tape.gradient(loss, [w, b]) # 자동 미분
opti.apply_gradients(zip(grad, [w, b]))
return loss
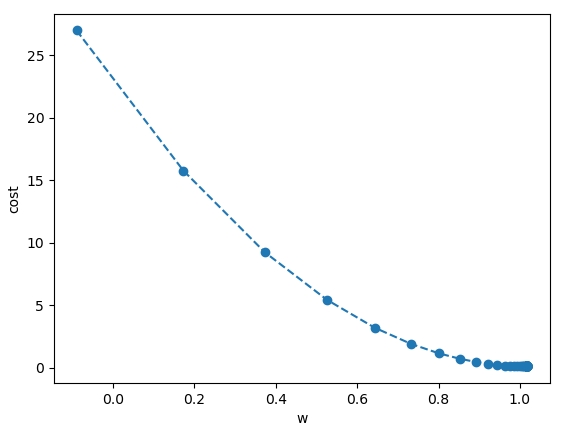
w_val = [] # 시각화 목적으로 사용
cost_val = []
for i in range(10):
loss = train_step3()
print('{:1}, w:{:4.3}, loss:{:4.5}, b:{:4.3}'.format(i, w.numpy(), loss.numpy(), b.numpy()))
w_val.append(w.numpy())
cost_val.append(loss.numpy())
'''
0, w: 5.0, loss:2500.0, b: 1.0
1, w: 7.4, loss:576.0, b:1.48
2, w:8.55, loss:132.71, b:1.71
3, w: 9.1, loss:30.576, b:1.82
4, w:9.37, loss:7.0448, b:1.87
5, w: 9.5, loss:1.6231, b: 1.9
6, w:9.56, loss:0.37397, b:1.91
7, w:9.59, loss:0.086163, b:1.92
8, w: 9.6, loss:0.019853, b:1.92
9, w:9.61, loss:0.0045738, b:1.92
'''
import matplotlib.pyplot as plt
plt.plot(w_val, cost_val, 'o')
plt.xlabel('w')
plt.ylabel('cost')
plt.show()
중앙값(median)과 IQR(interquartile range) 사용. 아웃라이어의 영향을 최소화
* ke8_scaler.py
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler, minmax_scale, StandardScaler, RobustScaler
data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/Advertising.csv')
del data['no']
print(data.head(2))
'''
tv radio newspaper sales
0 230.1 37.8 69.2 22.1
1 44.5 39.3 45.1 10.4
'''
# 모델 생성
model = Sequential()
model.add(Dense(1, input_dim =3)) # 레이어 1개
model.add(Activation('linear'))
model.add(Dense(1, input_dim =3, activation='linear'))
print(model.summary())
tf.keras.utils.plot_model(model,'abc.png')
tf.keras.utils.plot_model(model,'파일명') : 레이어 도식화하여 파일 저장.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import boston_housing
#print(boston_housing.load_data())
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
print(x_train[:2], x_train.shape) # (404, 13)
print(y_train[:2], y_train.shape) # (404,)
print(x_test[:2], x_test.shape) # (102, 13)
print(y_test[:2], y_test.shape) # (102,)
'''
CRIM: 자치시(town) 별 1인당 범죄율
ZN: 25,000 평방피트를 초과하는 거주지역의 비율
INDUS:비소매상업지역이 점유하고 있는 토지의 비율
CHAS: 찰스강에 대한 더미변수(강의 경계에 위치한 경우는 1, 아니면 0)
NOX: 10ppm 당 농축 일산화질소
RM: 주택 1가구당 평균 방의 개수
AGE: 1940년 이전에 건축된 소유주택의 비율
DIS: 5개의 보스턴 직업센터까지의 접근성 지수
RAD: 방사형 도로까지의 접근성 지수
TAX: 10,000 달러 당 재산세율
PTRATIO: 자치시(town)별 학생/교사 비율
B: 1000(Bk-0.63)^2, 여기서 Bk는 자치시별 흑인의 비율을 말함.
LSTAT: 모집단의 하위계층의 비율(%)
MEDV: 본인 소유의 주택가격(중앙값) (단위: $1,000)
'''
w = tf.Variable(tf.ones(shape=(1,)))
b = tf.Variable(tf.ones(shape=(1,)))
w.assign([2])
b.assign([2])
def func1(x): # 파이썬 함수
return w * x + b
print(func1(3)) # tf.Tensor([8.], shape=(1,), dtype=float32)
print(func1([3])) # tf.Tensor([8.], shape=(1,), dtype=float32)
print(func1([[3]])) # tf.Tensor([[8.]], shape=(1, 1), dtype=float32)
@tf.function # auto graph 기능 : tf.Graph + tf.Session. 파이썬 함수를 호출가능한 그래프 객체로변환. 텐서 플로우 그래프에 포함 되어 실행됨. 속도향상.
def func2(x): # 파이썬 함수
return w * x + b
print(func2(3))
v = tf.Variable(1) # 1
def find_next_odd(): # 파이썬 함수
v.assign(v + 1) # 2
if tf.equal(v % 2, 0): # 파이썬 제어문
v.assign(v + 10) # 12
@tf.function
def find_next_odd(): # auto graph 기능에 의해 tenserflow의 Graph 객체 환경에서 작업할 수 있도록 코드 변형.
v.assign(v + 1) # 2
if tf.equal(v % 2, 0): # Graph 객체 환경에서 사용하는 제어문으로 코드 변환
v.assign(v + 10) # 12
find_next_odd()
print(v.numpy()) # 12
=> @tf.function 사용 전 funcion 실행하여 정상 실행 여부 확인 후 추가.
def func():
temp = tf.constant(0)
# temp=0
su = 1
for _ in range(3):
temp = tf.add(temp, su)
# temp += su
return temp
kbs = func()
print(kbs) # tf.Tensor(3, shape=(), dtype=int32)
print(kbs.numpy(), ' ', np.array(kbs)) # 3 3
temp = tf.constant(0)
@tf.function
def func2():
#temp = tf.constant(0)
global temp
su = 1
for _ in range(3):
temp = tf.add(temp, su)
return temp
mbc = func2()
print(mbc) # tf.Tensor(3, shape=(), dtype=int32)
global
#@tf.function 사용불가
def func3():
temp = tf.Variable(0)
su = 1
for _ in range(3):
#temp = tf.add(temp, su)
temp = temp +su #temp += su 불가
return temp
sbs = func3()
print(sbs)
=> tf.Variable() 내부에 사용시 @tf.function 사용불가
temp = tf.Variable(0) # auto graph 외부에 선언
@tf.function
def func4():
su = 1
for _ in range(3):
#temp = tf.add(temp, su) 불가
#temp = temp +su 불가
temp.assign_add(su) # 누적방법
return temp
ytn = func4()
print(ytn)
=> tf.Variable() 외부에 사용시 @tf.function 사용 가능하며 누적은 temp.assign_add(su)로만 가능
# 구구단
@tf.function
def gugu1(dan):
su = 0
for _ in range(9):
su = tf.add(su, 1)
# print(su.numpy())
# AttributeError: 'Tensor' object has no attribute 'numpy'
# print('{} * {} = {:2}'.format(dan, su, dan * su))
# TypeError: unsupported format string passed to Tensor.__format__
print(gugu1(3))
=> @tf.function사용 시 numpy() 강제 형변환, format 사용 불가.
@tf.function
def gugu2(dan):
for i in range(1, 10):
result = tf.multiply(dan, i)
# print(result.numpy()) # AttributeError: 'Tensor' object has no attribute 'numpy'
print(result)
print(gugu2(3))
연산자와 기본 함수
* tf5.py
import tensorflow as tf
import numpy as np
x = tf.constant(7)
y = 3
# 삼항 연산
result1 = tf.cond(x > y, lambda:tf.add(x,y), lambda:tf.subtract(x, y))
print(result1, ' ', result1.numpy()) # tf.Tensor(10, shape=(), dtype=int32) 10
tf.cond(조건, 참일때 실행함수, 거짓일때 실행함수) : 삼항연산자
# case 조건
f1 = lambda:tf.constant(1)
print(f1) # 주소
f2 = lambda:tf.constant(2)
print(f2()) # 실행값
a = tf.constant(3)
b = tf.constant(4)
result2 = tf.case([(tf.less(a, b), f1)], default=f2)
print(result2, ' ', result2.numpy()) # tf.Tensor(1, shape=(), dtype=int32) 1
print()
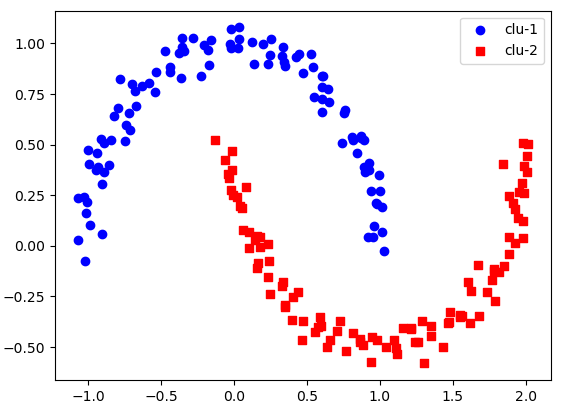
plt.scatter(x[pred==0, 0], x[pred==0, 1], c = 'red', marker='o', label='cluster1')
plt.scatter(x[pred==1, 0], x[pred==1, 1], c = 'green', marker='s', label='cluster2')
plt.scatter(x[pred==2, 0], x[pred==2, 1], c = 'blue', marker='v', label='cluster3')
plt.scatter(kmodel.cluster_centers_[:, 0], kmodel.cluster_centers_[:, 1], c = 'black', marker='+', s=50, label='center')
plt.legend()
plt.grid(True)
plt.show()
# 몇개의 그룹으로 나눌지가 중요. k의 값.
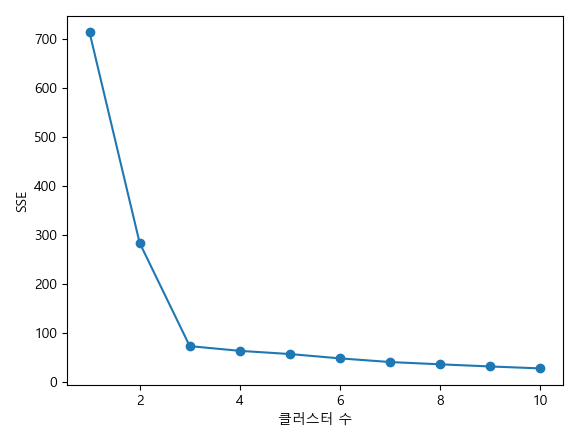
# 방법 1 : elbow - 클러스터간 SSE(오차 제곱의 함, sum of squares error)의 차이를 이용해 k 개수를 알 수 있다.
plt.rc('font', family = 'malgun gothic')
def elbow(x):
sse = []
for i in range(1, 11): # KMeans 모델을 10번 실행
km = KMeans(n_clusters = i, init='k-means++', random_state = 0).fit(x)
sse.append(km.inertia_)
print(sse)
plt.plot(range(1, 11), sse, marker='o')
plt.xlabel('클러스터 수')
plt.ylabel('SSE')
plt.show()
elbow(x) # k는 3을 추천
# 방법 2 : silhoutte
'''
실루엣(silhouette) 기법
클러스터링의 품질을 정량적으로 계산해 주는 방법이다.
클러스터의 개수가 최적화되어 있으면 실루엣 계수의 값은 1에 가까운 값이 된다.
실루엣 기법은 k-means 클러스터링 기법 이외에 다른 클러스터링에도 적용이 가능하다
'''
import numpy as np
from sklearn.metrics import silhouette_samples
from matplotlib import cm
# 데이터 X와 X를 임의의 클러스터 개수로 계산한 k-means 결과인 y_km을 인자로 받아 각 클러스터에 속하는 데이터의 실루엣 계수값을 수평 막대 그래프로 그려주는 함수를 작성함.
# y_km의 고유값을 멤버로 하는 numpy 배열을 cluster_labels에 저장. y_km의 고유값 개수는 클러스터의 개수와 동일함.
def plotSilhouette(x, pred):
cluster_labels = np.unique(pred)
n_clusters = cluster_labels.shape[0] # 클러스터 개수를 n_clusters에 저장
sil_val = silhouette_samples(x, pred, metric='euclidean') # 실루엣 계수를 계산
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(cluster_labels):
# 각 클러스터에 속하는 데이터들에 대한 실루엣 값을 수평 막대 그래프로 그려주기
c_sil_value = sil_val[pred == c]
c_sil_value.sort()
y_ax_upper += len(c_sil_value)
plt.barh(range(y_ax_lower, y_ax_upper), c_sil_value, height=1.0, edgecolor='none')
yticks.append((y_ax_lower + y_ax_upper) / 2)
y_ax_lower += len(c_sil_value)
sil_avg = np.mean(sil_val) # 평균 저장
plt.axvline(sil_avg, color='red', linestyle='--') # 계산된 실루엣 계수의 평균값을 빨간 점선으로 표시
plt.yticks(yticks, cluster_labels + 1)
plt.ylabel('클러스터')
plt.xlabel('실루엣 개수')
plt.show()
'''
그래프를 보면 클러스터 1~3 에 속하는 데이터들의 실루엣 계수가 0으로 된 값이 아무것도 없으며, 실루엣 계수의 평균이 0.7 보다 크므로 잘 분류된 결과라 볼 수 있다.
'''
X, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=0.5, shuffle=True, random_state=0)
km = KMeans(n_clusters=3, random_state=0)
y_km = km.fit_predict(X)
plotSilhouette(X, y_km)
* cluster4.py
# 숫자 이미지 데이터에 K-평균 알고리즘 사용하기
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits() # 64개의 특징(feature)을 가진 1797개의 표본으로 구성된 숫자 데이터
print(digits.data.shape) # (1797, 64) 64개의 특징은 8*8 이미지의 픽셀당 밝기를 나타냄
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits.data)
print(kmeans.cluster_centers_.shape) # (10, 64) # 64차원의 군집 10개를 얻음
# 군집중심이 어떻게 보이는지 시각화
fig, ax = plt.subplots(2, 5, figsize=(8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks=[])
axi.imshow(center, interpolation='nearest')
plt.show() # 결과를 통해 KMeans가 레이블 없이도 1과 8을 제외하면
# 인식 가능한 숫자를 중심으로 갖는 군집을 구할 수 있다는 사실을 알 수 있다.
# k평균은 군집의 정체에 대해 모르기 때문에 0-9까지 레이블은 바뀔 수 있다.
# 이 문제는 각 학습된 군집 레이블을 그 군집 내에서 발견된 실제 레이블과 매칭해 보면 해결할 수 있다.
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
# 정확도 확인
from sklearn.metrics import accuracy_score
print(accuracy_score(digits.target, labels)) # 0.79354479
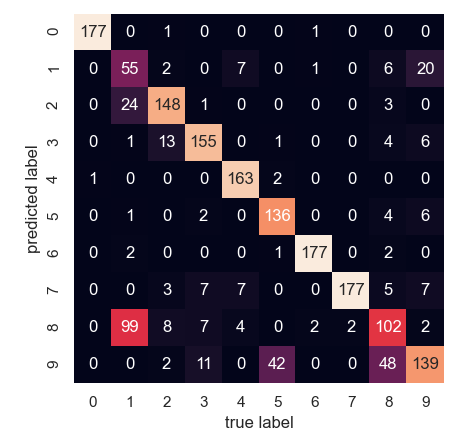
# 오차행렬로 시각화
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(digits.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=digits.target_names,
yticklabels=digits.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label')
plt.show() # 오차의 주요 지점은 1과 8에 있다.
# 참고로 t분포 확률 알고리즘을 사용하면 분류 정확도가 높아진다.
from sklearn.manifold import TSNE
# 시간이 약간 걸림
tsne = TSNE(n_components=2, init='random', random_state=0)
digits_proj = tsne.fit_transform(digits.data)
# Compute the clusters
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits_proj)
# Permute the labels
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
# Compute the accuracy
print(accuracy_score(digits.target, labels)) # 0.93266555